「Grafana Cloud」の先進的ユーザーであるグリーが10年をかけて到達した「オブザーバービリティ」とは

- 1 グリーが10年をかけて築いたオブザーバービリティの進化
- 2 グリーのオブザーバービリティ戦略と今後の展望
- 2.1 セッションでは、オンプレミスからクラウドへの移行の前にGangliaからGrafanaへ変更した経緯が解説されていましたが、岩堀さんはツールの選定にも関わっていたのですか。
- 2.2 AWSではオープンソース版のGrafanaを使用していましたが、GKEのインフラストラクチャーへ移行する際にクラウドサービス版を選択したのはどのような理由からですか。
- 2.3 今回のカンファレンスではScripted-Dashboard機能が将来的に廃止されることが何度も説明されていました。グリーのダッシュボードでもこの機能を使用しているかと思いますが、それについて不安はありませんか。
- 2.4 「オブザーバービリティ」と言うとログやメトリクスの話が中心になりますが、アプリケーションの性能を分析するAPM(Application Performance Monitoring)の領域については、どのようにお考えですか。
- 2.5 今後の展望についてお聞きしたいのですが、将来的にグリーのオブザーバービリティはどのように進化していくと考えていますか。
- 2.6 「ハイブリッド」という言葉が何度か出てきましたが、これは複数のパブリッククラウドを使い分ける「マルチクラウド」とは異なる概念なのでしょうか。
- 2.7 最後に、Grafana Labsに対して要望があればお聞かせください。
- 3 まとめ
クラウドネイティブなシステムのオブザーバービリティに使われる可視化ツールとして代表的なツール、Grafanaの開発元であるGrafana Labsがテクニカルカンファレンス「ObservabilityCON on the Road」を日本で初めて2025年2月25日に都内で開催した。
本稿では、カンファレンスの個別セッションで登壇した株式会社グリーのインフラストラクチャー部門でモニタリングを担当するシニアリードエンジニア、岩堀 草平氏による同社のメトリクス基盤として「Grafana Cloud」を採用し、どのようにマルチクラウド環境に適応していったのか、また長期間の運用で発生した課題やその対応について講演した内容と、同氏へのインタビューの模様をお届けする。

「ObservabilityCON on the Road」で基調講演を行った岩堀 草平氏
グリーが10年をかけて築いた
オブザーバービリティの進化
セッションで岩堀氏は、グリーにおけるメトリクス基盤の進化とその課題について解説した。グリーでは、2015年頃のAWS移行を契機に、メトリクス基盤としてOSSのGrafanaとPrometheusの導入を開始。その後、2020年にはGKE環境でGrafana Cloudの利用を開始し、2021年にはオンプレミス環境も従来のGangliaベースのシステムからGrafana Cloudへと移行したという。これにより、オンプレミス、AWS、Google Cloudのすべてのメトリクス基盤がGrafanaに統一された。
また、Grafana/Prometheusスタックを採用した理由や、マルチクラウド環境への適応、長期間の運用で直面した課題とその対応策について語られた。

Grafanaを10年間使ってきた経験を解説する岩堀氏のセッション
岩堀氏はまず、グリーのインフラストラクチャーの規模について説明し、60のインスタンスが稼働しており、それらが3つの異なる環境に分類されることを紹介した。
この3つの環境とは、
- オンプレミス環境に構築された仮想マシンベースのインフラストラクチャー
- Amazon Elastic Kubernetes Service(Amazon EKS)を活用したAWS上のKubernetesクラスター
- Google Kubernetes Engine(GKE)を用いたGoogle Cloud上のKubernetesクラスター

グリーのインフラストラクチャーの概要。3つのタイプが存在する
その内容を解説したスライドでは、3つのタイプのインフラストラクチャーに対し、主にGrafanaのソリューションを、タイムシリーズデータベースであるPrometheusと組み合わせて活用していることが紹介された。

岩堀氏が所属するモニタリングユニットが提供するオブザーバービリティの概要
主にゲームの特性に起因する高い応答性への対応と、ビジネスサイドからの要求である年単位での比較分析を可能にするため、長期間のメトリクス保存が求められていることが紹介された。 これにより、ゲームというビジネスモデルに適した監視基盤の必要性が明確になった。
また、監視対象となるシステムの構成についても、3つのタイプをそれぞれ紹介。特に、GKE上のコンテナークラスターからGrafana Cloudへ連携する仕組みについて詳しく解説された。
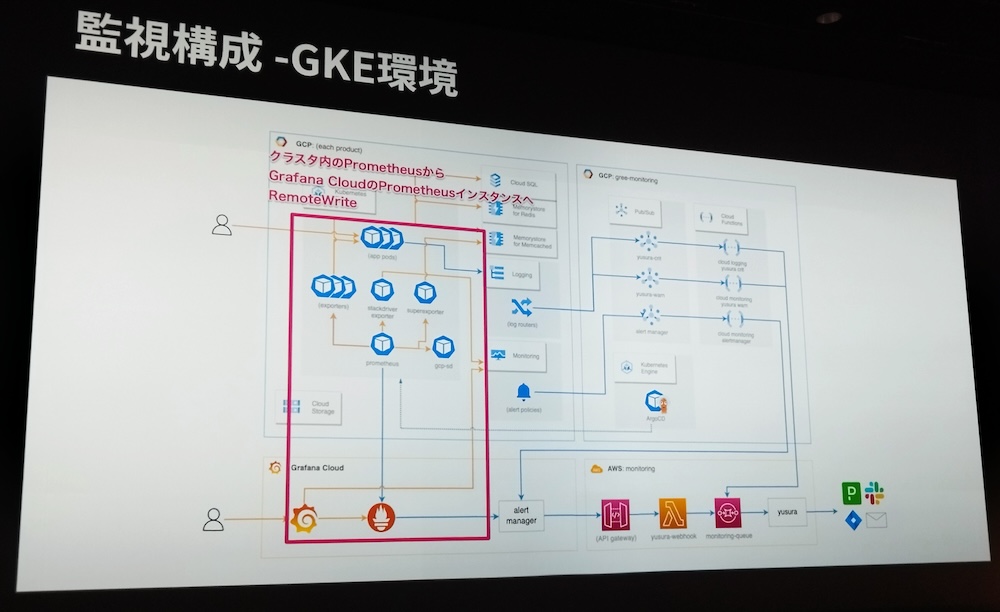
GKEからGrafana Cloudへの連携するシステム構成を解説
EKS/AWSではオープンソース版のGrafanaを、GKE/GCPではGrafana Cloudを活用し、同じユーザー体験を提供することがモニタリングユニットの発想であったことが紹介された。これにより、インフラストラクチャーが異なっても、統一された観測性を維持することを目指したチームの取り組みが強調された。
また、オンプレミス環境をクラウドサービスへ移行するためのアプローチとして、シンプルな構成を追求し、既存のGanglia環境の機能を代替するパッケージやダッシュボードを提供したことが説明された。これは、オンプレミスからクラウド移行を検討しているエンジニアにとっては参考となる内容だろう。

オンプレミスの監視基盤のアプローチ
最後に、10年にわたりオンプレミス環境からオープンソースを活用したクラウドサービス、さらにマネージドなクラウドサービスへと移行を経験したエンジニアとしての知見が解説された。
ここでは、インフラストラクチャーが変わっても同じユーザー体験を提供することの重要性や、「ダッシュボードの民主化」と呼ばれる、ユーザーが自由にカスタマイズできるダッシュボード機能について説明が行われた。
さらに、PrometheusがKubernetesのデファクトスタンダードとなったことでエコシステムが活性化し、コミュニティによるツールやソフトウェアの発展によって、よりリッチな監視基盤の構築が可能になったことが語られ、セッションは締めくくられた。

グリーの10年を掛けたGrafanaによる監視基盤移行の振り返り
グリーのオブザーバービリティ戦略と今後の展望
ここからは、セッションで紹介されたグリーの監視基盤の変遷やクラウド移行の背景を踏まえ、岩堀氏が現場で直面した課題や技術的な判断について詳しく伺ったインタビューをお届けする。
セッションでは、オンプレミスからクラウドへの移行の前にGangliaからGrafanaへ変更した経緯が解説されていましたが、岩堀さんはツールの選定にも関わっていたのですか。
私は直接ツールの選定には関わっていませんでしたが、グループのエンジニアが評価を行いました。Gangliaからの移行にあたっては、大規模な分散システムに適したツールを選定するという観点で評価が行われたはずです。その際、タイムシリーズデータベースとしてPrometheusが最適だという結論が社内で出ていました。
もう1つの理由として、オンプレミス環境ではインスタンスの変動が少ないのに対し、クラウド環境ではサーバーを必要に応じて起動・停止するため、自動的にインスタンスを検出できる仕組みが求められました。そこで、サービスディスカバリー機能を備えたPrometheusが適していたこと、さらにPrometheusと最も相性の良い監視基盤としてGrafanaが選ばれたことが決め手となったようです。 グリーのシステムでは、カスタムメトリクスを重視し、それを高度に活用していたため、それらをPrometheusとGrafanaの組み合わせで柔軟に実装できることも、採用の大きな要因となりました。

株式会社グリー シニアリードエンジニア 岩堀 草平氏
AWSではオープンソース版のGrafanaを使用していましたが、GKEのインフラストラクチャーへ移行する際にクラウドサービス版を選択したのはどのような理由からですか。
ちょうどその頃、Grafana Cloudが利用可能になったことも大きな要因の1つでした。すでにAWSでGrafanaを使用していたため「GKEでも同じユーザー体験を維持したい」という意図もありました。
また、グリーのビジネス領域の開発を担当するデベロッパーは「監視基盤そのものに手間をかけたくない」という考えもあったと思います。そのため「運用負担を軽減しながら同じ監視環境を提供できるGrafana Cloudの採用が最適だった」という判断に至りました。
今回のカンファレンスではScripted-Dashboard機能が将来的に廃止されることが何度も説明されていました。グリーのダッシュボードでもこの機能を使用しているかと思いますが、それについて不安はありませんか。
Scripted-Dashboardの廃止は数年前から公表されていたので、特にショックはありませんでした。しかし、この機能を活用しているのは比較的Grafanaを使い込んでいるユーザーが多いと思うので、今後の移行方針については多少の不安はありました。
ただ、今回Grafana Scenesが発表され、React.jsのコードを書けば同様の機能が実現できることが分かったので、書き直しの作業は必要になりますが安心感は得られました。
「オブザーバービリティ」と言うとログやメトリクスの話が中心になりますが、アプリケーションの性能を分析するAPM(Application Performance Monitoring)の領域については、どのようにお考えですか。
現在、APMについては他のツールを使用して実施していますが、「OpenTelemetry」が登場して事実上のデファクトスタンダードとなったことで、状況が変わりつつあります。
Grafanaには「Tempo」というトレーシングツールがあり、それと組み合わせることでAPMの実現も可能になると考えています。 そのため、現在は導入の可能性を含めて検討を進めている段階です。
今後の展望についてお聞きしたいのですが、将来的にグリーのオブザーバービリティはどのように進化していくと考えていますか。
現在のクラウド環境をさらに拡大するというよりは、トレーシングやプロファイリングなどの機能を組み合わせて、より高度なオブザーバービリティを実現したいと考えています。
現時点ではAWSとGCPを組み合わせたハイブリッドな環境を構築していますが、今後は観測できる領域を広げる方向で発展させていく予定です。
「ハイブリッド」という言葉が何度か出てきましたが、これは複数のパブリッククラウドを使い分ける「マルチクラウド」とは異なる概念なのでしょうか。
そうですね、一般的な定義では「ハイブリッドクラウド」はオンプレミスとクラウドを組み合わせた環境を指すと思います。
今回のお話の中ではオープンソースとマネージドサービスを異なるクラウドプラットフォーム上で組み合わせて運用する意味で「ハイブリッド」という言葉を使っていました。
最後に、Grafana Labsに対して要望があればお聞かせください。
クラウドサービスを利用する以上、エンジニアであっても毎月の請求額は気になってしまいます。為替レート(円ドルレート)の影響もあるため一概には言えませんが、やはり価格は安いに越したことはありませんからね。
また、グリーのビジネスの特性かもしれませんが、新しいゲームのリリースやキャンペーンなど、短期間で大量のリソースを消費するケースが多くあります。そういった場面では、通常の料金体系とは異なる、短期間のみ利用できるインスタンス向けの価格プランがあると、ユーザーとしては非常にありがたいですね。
まとめ
ダイナミックに変動するインフラストラクチャーやアプリケーションのオブザーバービリティに関しては「Grafanaのソリューションに満足している」と語る岩堀氏。
一方で、プロファイリングやトレーシング、新しいダイナミックなダッシュボード、さらにはAPM(Application Performance Monitoring)といったシステムの可視化に対しては、大きな期待を寄せていることが伝わるインタビューとなった。


連載バックナンバー


Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- Grafana Labs CTOのTom Wilkie氏インタビュー。スクラップアンドビルドから産まれた「トラブルシューティングの民主化」とは
- CNDT2021、ミクシィのSREによるEKS移行の概要を解説するセッションを紹介
- KubeCon Europe 2024にて、New RelicのEMEA担当CTOにインタビュー
- カオスエンジニアリングのOSS、LitmusChaosの概要を解説するCNCFのウェビナーを紹介
- KubeCon Europe 2023共催のLinkerd Dayからアディダスの事例セッションを紹介
- Observability Conference 2022から、サイボウズのオブザーバービリティ事例を紹介
- CloudNative Days Fukuoka 2023、GoogleによるGKE上のGateway APIの解説セッションを紹介
- CNDT2021、日本オラクルのエンジニアによるクラウドネイティブを再確認するセッション
- eBPF Summit、eBPFとKubernetesでコアネットワーク構築? Bell Canadaのセッションを紹介
- KubeCon North America 2024、日本からの参加者を集めて座談会を実施。お祭り騒ぎから実質的になった背景とは?