KubeCon Europe 2025、3日目のキーノートでGoogleとByteDanceが行ったセッションを紹介

KubeCon Europe 2025の3日目のキーノートセッションから、GoogleとByteDanceのエンジニアが行ったセッションを紹介する。これは大規模言語モデル(LLM)のチューニング技術であるLoRA(Low-Rank Adaptation)によってチューニングされたモデルを、Kubernetes上で実装した際に複数のレプリカにロードバランスを行う新しいプロジェクトを解説したものだ。

登壇したGoogleのCrayton Coleman氏(左)とByteDanceのJiaxin Shan氏(右)
GoogleとByteDanceのエンジニアが協同でプレゼンテーションを行うというのも意外な組み合わせである。また、推論モデルへのロードバランシングをGateway APIの拡張機能として実装するという、あくまでもKubernetesの作法に従った実装を目指しているのが、ポイントと言える。
最初にColeman氏がLLMの進化について解説。ここでは小規模なモデルから大規模モデルへの進化だけではなく、プロプライエタリーなモデルからオープンなモデルへの変化、そしてモデルを実行するプラットフォームが徐々にKubernetesに移行していった流れを解説している。
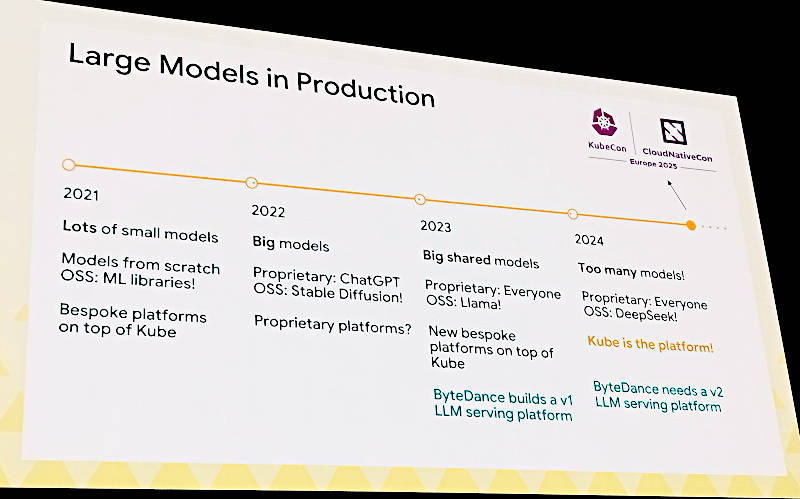
大規模モデルの進化を解説
そしてここからはByteDanceのShan氏がプレゼンテーションを引き継ぎ、LLMによる推論がその他のアプリケーションとは異なることを解説した。特にLLMにおいては入力されたプロンプトと出力される推論結果の長さに相関が薄く、処理に必要となる計算資源(CPUやGPUコア)がクエリーの数に関係なく大量に消費されてしまうことを解説。この辺りはByteDanceが実際にプロダクションシステムで経験している内容を元にしていると思われる。
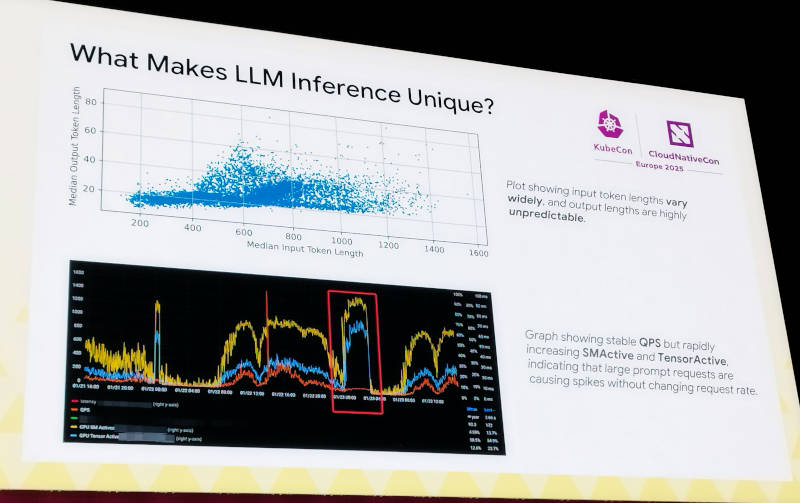
クエリーの数に相関しないLLMの実態。少ないプロンプトでもCPU資源の大量消費が発生する
ByteDanceの経験から実行に使われるGPUのモデルは多様であり、プロンプトの長さに関わらず負荷が増大してしまう状況に対して、通常のロードバランサーでは負荷を均すことは難しいということを解説した。次のスライドを見ると、ByteDanceの持つGPUクラスターのタイプが8種類あり、ノード数は100未満から8000弱までとなっていることがわかる。GPUのモデルによってここまで多様化してしまうのは、そもそもGPUの調達が難しいということも背景にあるだろうと予測される。とにかく手に入れられるGPUを全部購入する発想なら、機種を揃えるということは難しいだろう。

多様なGPUモデルを使いこなすByteDanceのクラスター資源
これらの問題点を整理したうえでオンプレミスのLLM実装に対するロードバランサーとして求められるのはDenser、Faster、Automatedという特徴であると説明。Denserは凝縮という意味で、GPUへのスケジューリングを効率的に行うということだろう。Fasterはロードバランサーによって単一のモデルによって実行されるよりも複数のモデルを並列化することでGPUクラスター全体の実行速度が高速化されること、そしてAutomatedは並列化されたクラスターの増減をマニュアルで行うのではなく、自動化するという意味だと思われる。

3つのポイントで並列化されるLLM実行を解説
ここではLoRA(Low-Rank Adaptation)そのものについての詳細な解説は行わず、GPUクラスターで実行されるアプリケーションが偏ってしまうことなどを問題点として挙げた。
次のスライドでは実際にByteDanceが使っていると思われるVolcanoのダッシュボードを使って並列実行されているGPUクラスターに対するリクエストの配分を変えることで1.5倍から4.7倍のコストセービングが達成できたとことを示している。ここではゲートウェイがロードバランサーの役割、アダプターがLLMアプリケーションに付属するProxy的なソフトウェアという意味だろう。いずれにせよLoRAによってチューニングされたLLMアプリケーションを並列化し、ゲートウェイがロードバランサーとしてリクエストを配分、必要があればLLMを追加起動してリクエストを捌くというクラウドネイティブなシステムと基本的には同じ発想で実装されることで、Kubernetesの上にLLMを載せて遅延なく実行するということが可能になるというのがこのセッションの落としどころだろう。
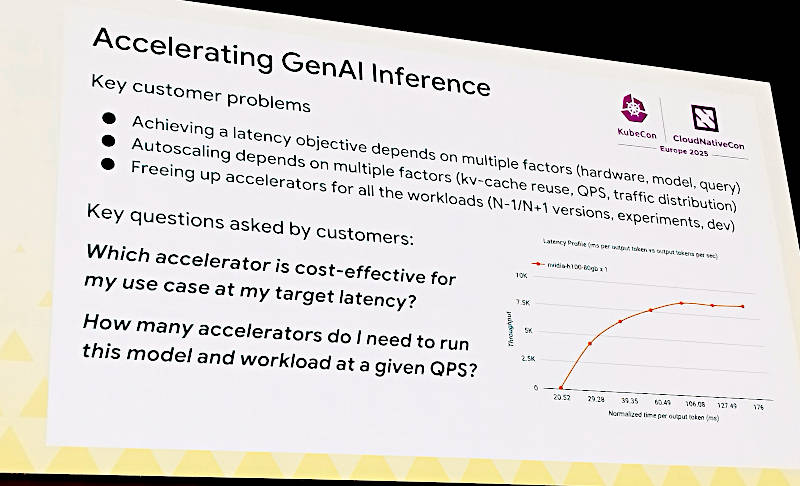
生成AIの推論を高速化するためのポイントを整理
ここではLoRAでチューニングされたアプリケーションは従来のアプリケーションとは異なり、リクエストの数はリクエストの長さだけでは計算できず、短いリクエストでも大量のGPU/CPU資源を使ってしまうという状況が起こり得ること、そしてそれに対して負荷をモニタリングしながらワークロードを調整して配備する戦略が必要だと説明し、ロードバランサーがその主な役割を担うと説明した。
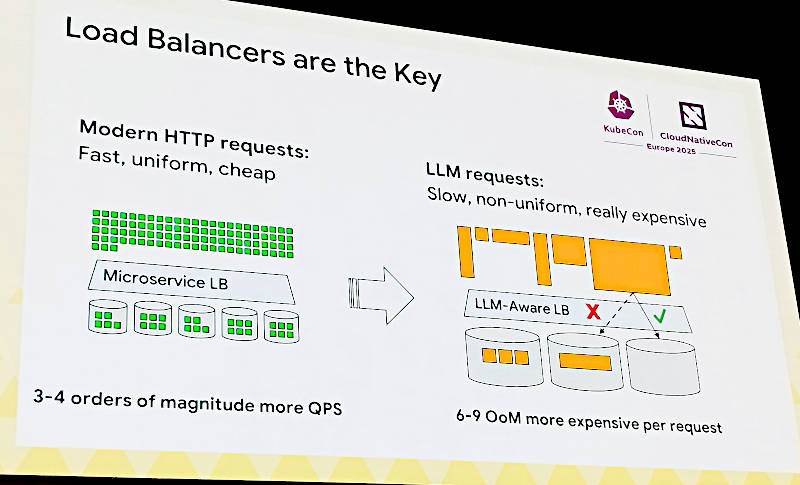
単純なロードバランシング戦略ではLLMの実行には不足してしまう
このスライドで左側はマイクロサービスとして実装されているロードバランサーが大量のリクエストを複数のアプリケーションに配分することでレイテンシーを低く保っていたシステムは右側に描かれているLLMの実行には向いておらず、LLMのへのリクエストを効率的に配分できるLLMアプリケーションに特化したロードバランサーが必要だと説明した。

LLMに特化したロードバランサーとは何か?
ここではリクエストを受け取ったロードバランサーが単純にラウンドロビンなどの戦略で配分するのではなく、アプリケーションが実行した結果(メトリクスなど)をコレクターが収集し、それをロードバランサーに付随するアルゴリズムに返すことでどのようなリクエストがどのくらいの処理資源を必要としたのか? を計算する。そしてその結果から次のリクエストが消費するであろう資源を予想したうえで、最も効率的に実行できるクラスターにジョブを割り当てるという戦略が必要であることを説明した。ここではそのアルゴリズムは安価なCPUでも実行でき、その結果として高価なGPUクラスターをより効果的に使うことができるという点を強調している。
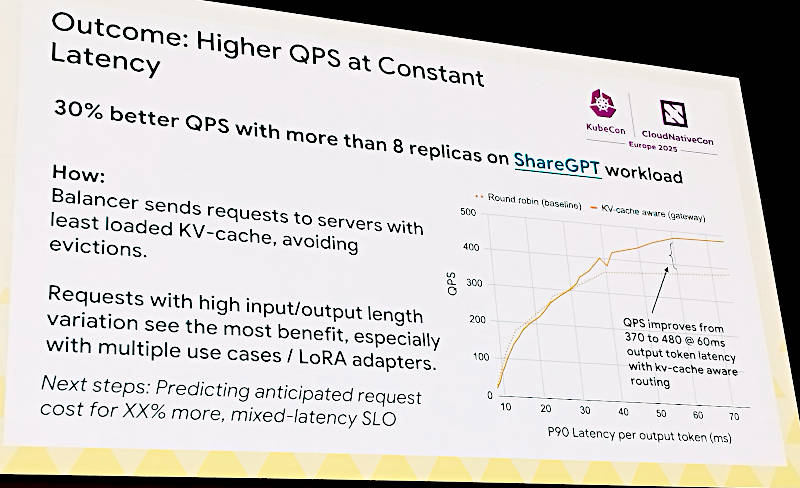
ロードバランサーを変えた結果を紹介。8レプリカのクラスターで30%のレイテンシー改善
この変更によって8つのレプリカで並列化されたGPUクラスターではQPS(Query per Second)において30%の向上が見られたという。この改善された値はkv-cacheを使ったルーティングという部分に関係する。これはロードバランサーがリクエストを送るノードを選択する際に最もkv-cacheを使用していないノードを選ぶことにより、システム全体でキャッシュが消されずに再利用されることで高速化が行われるという意味だと思われる。
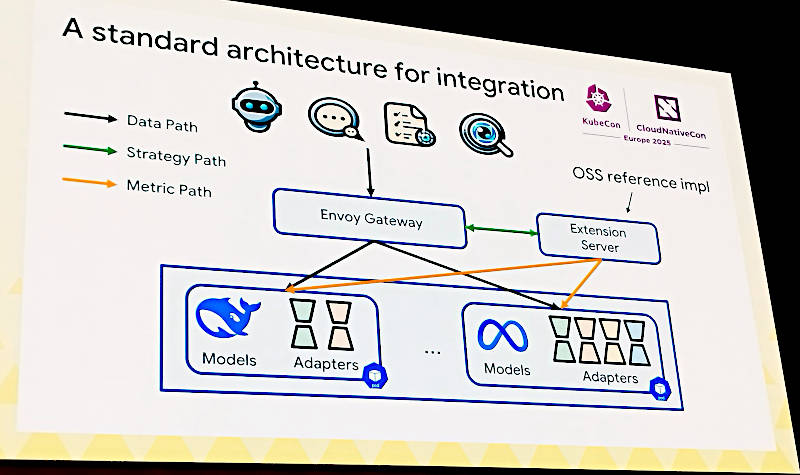
新しいロードバランサーのアーキテクチャー
ここではこのロードバランサーを実装する際のアーキテクチャーを解説。Envoy Gatewayがロードバランサーとして配備されるが、その脇にExtension Serverが存在する。これが2つ前のスライド、LLMに特化したロードバランサーで言うところの「アルゴリズム」を実装する場所だ。Envoy Gatewayからデータが流れ、各モデルで実行されたメトリクスはExtension Serverが収集、その評価の結果をEnvoy Gatewayに伝えて最適なワークロードの振り分けが行われるという発想だ。

標準的なKubernetesクラスターと同様のオーケストレーションの実装へ
結果としてKubernetes上で実装されるLoRAアプリケーションは、単にリクエストの数だけではなく推論の結果をメトリクスとして評価することで、モデル実行の最適化が可能になると説明した。
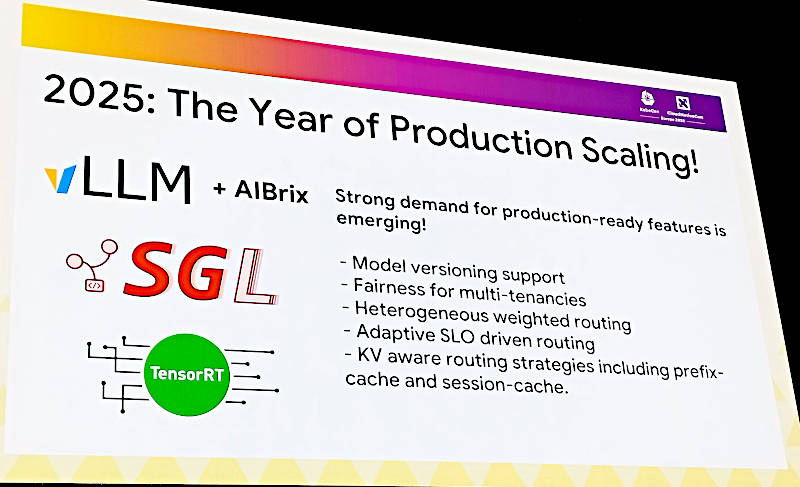
2025年は生成AI実行がスケーリングできるようになった年になると宣言
ここではLLMをKubernetes上で実行するというニーズは高まっており、従来の方法とは異なるアルゴリズム(Extension Server)を取り入れることで本番環境でも使えるスケジューリング、オーケストレーションが可能になると説明した。ここではvLLMとAIBrixが真っ先に挙げられている。vLLMは高スループットのLLMライブラリ、AIBrixは2024年にByteDanceが開発を開始したvLLMをベースにしたKubernetes用のスタックである。AIBrix自体がvLLMのプロジェクトに含まれていることから、vLLMをKubernetes上で使えるようにしたソフトウェアとも読める。またGoogleとAnyscaleが共同開発者としても挙げられていることから、GoogleとByteDanceがvLLMプロジェクトの中でKubernetes上のモデルサービングに関して本番環境のフィードバックをもとに作り上げたスケジューラー/オーケストレーターだということもわかる。興味のある方は以下の公式GitHubページを参照して欲しい。
●公式GitHub:https://github.com/vllm-project/aibrix
すでにKubernetesの公式SIGとしても情報が公開されているので、そちらを先に参照するべきかもしれない。
●参考:https://gateway-api-inference-extension.sigs.k8s.io/

公式SIGのページを紹介
ここではゲートウェイとしてEnvoyだけではなくIstioや今回のKubeConでSoloが発表したkgatewayも対象に挙がっているのが興味深い。
kgatewayについては以下のCNCFの告知を参照されたい。
●参考:Advancing Open Source Gateways with kgateway
実際にワークロードを実行するプラットフォームとして、vLLMだけではなくNVIDIAやGoogleも挙げられている。Googleが協力している以上、無視はできなかったということだろうか。
単体のGPUを最適化するスケジューリング問題や、LLMの実装というレベルの少しだけ上の階層の複数のLLMを実行した際のレイテンシーに着目して、ロードバランサーをKubernetesのアーキテクチャーからは離れないように設計しながら、利用するコンポーネントやプラットフォームを入れ替えられるようにするというクラウドネイティブなシステムの基本を守った感の強いプロジェクトの説明となった。GoogleとByteDanceというAIの実装と本番活用のリーダー企業が主導しているプロジェクトとして注目していきたい。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています




全文検索エンジンによるおすすめ記事
- KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
- KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
- Kubernetesの新しいネットワーク機能、Gateway APIを理解する(後編)
- OpenStack Summit 2018、Yahoo!ジャパンが共同開発するGimbalとは?
- Kubernetesの新しいネットワーク機能、Gateway APIを理解する(前編)
- All Things OpenからSolo.ioのBrian Gracely氏にインタビュー。サイドカーレスサービスメッシュとは?
- EnvoyをベースにしたAPI GatewayのGlooが最新バージョン1.3をリリース
- CNDT2021、HPEのアーキテクトが解説するKubernetesネットワークの最新情報
- サービスメッシュのLinkerd 2.9を紹介。EWMA実装のロードバランサー機能とは
- KubeCon NA 2024開催、前日の共催カンファレンスからAIワークロードのスケジューリングに関するセッションを紹介