Rancher Pipelineを使ったCI/CD

Rancher Pipelineの構築
Rancher Pipelineを設定するにはWorkloadのPipelinesから対象のリポジトリを選択して、Edit Configをクリックします(図16)。
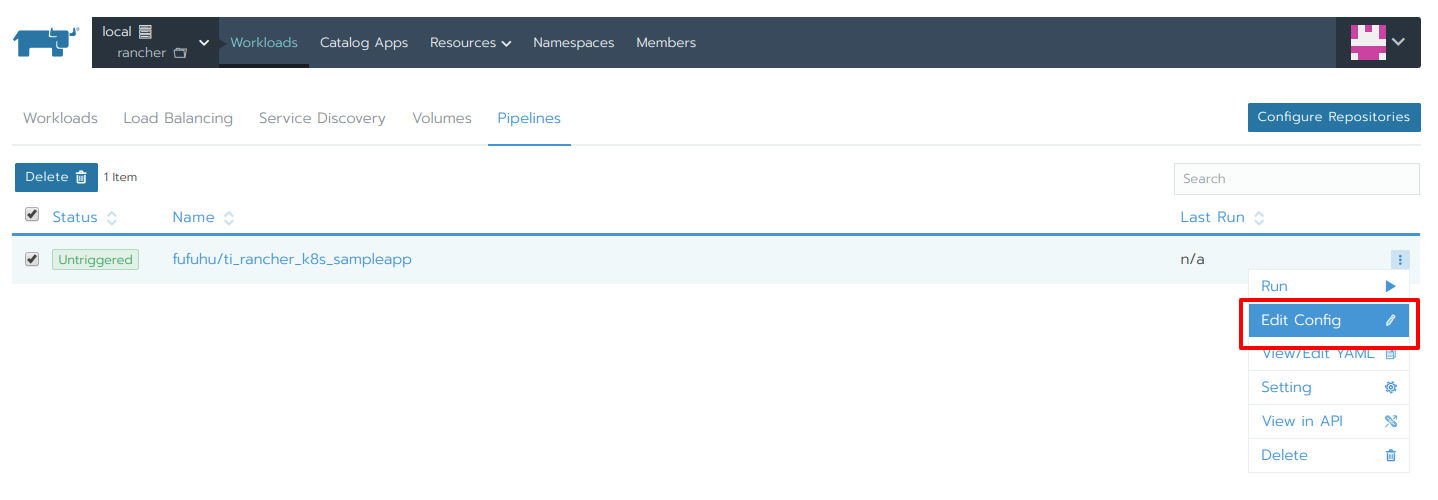
図16:Pipelineの設定
パイプラインを設定するgitのブランチを指定します(図17(1))。現時点ではパイプラインの設定(.rancher-pipeline.ymlファイル)は対象ブランチに含まれていないので、Configure pipeline for this branchをクリックします(図17(2))。
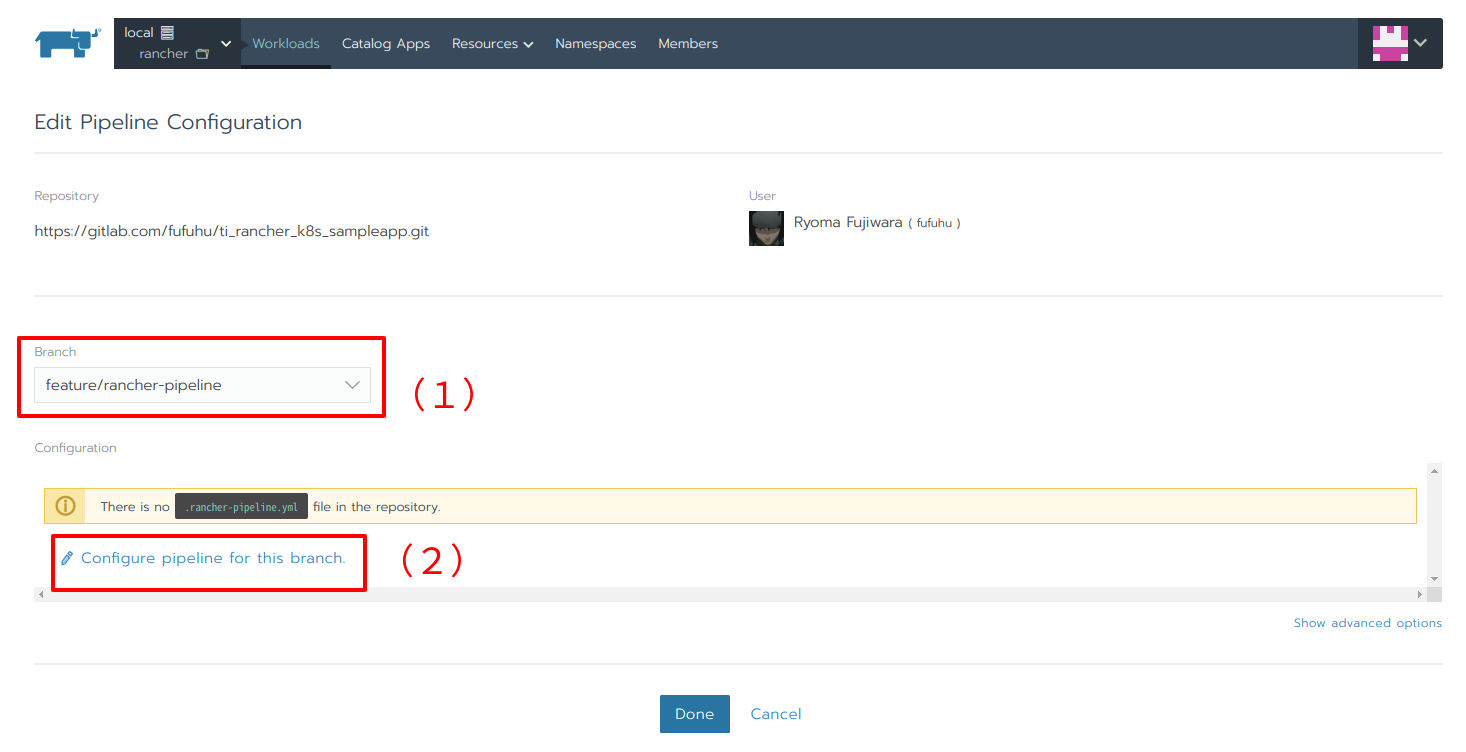
図17:パイプラインの設定画面
今回は、ビルド(Build)、テスト(Test)、デプロイ(Deploy)の3ステージから構成されるパイプラインを準備します。以降はそれぞれのパイプラインのステージを設定していく様子を示します。
Buildステージの構築
Buildステージでは、サーバアプリケーションのコンテナイメージのビルドを行い、GitLab CRにプッシュすることを目的としています。まず、Add Stageボタンをクリックします(図18)。
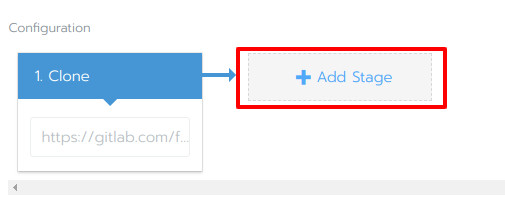
図18:ステージの追加
ステージ名を設定するためのモーダルウインドウが開きます(図19)。ここではBuildを設定(図19(1))し、Addボタンをクリックします(図19(2))。
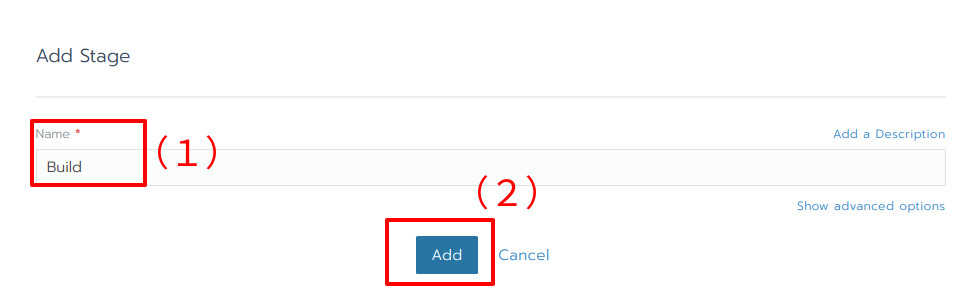
図19:ステージ名の設定
Buildステージに含まれるステップを作成します。続いてAdd a Stepボタンをクリックします(図20)。
図20:ステップの追加
ステップの詳細設定を行うためのモーダルウインドウが表示されます(図21)ので、必要な項目を設定していきます。
今回はDockerコンテナイメージのビルドなので、ステップの種類にはBuild and Publish Imageを選択します(図21(1))。次に、Dockerfileのパスを指定します(docker buildの-fオプションに対応、図21(2))。さらに、イメージの名前を指定します(docker buildの-tオプションに対応、図21(3))。次の図21(4)は、ビルドが終わった後にイメージをレジストリにプッシュするかどうかの設定です。今回はGitLab CRにイメージをプッシュしたいので、有効化します。図21(5)はイメージをプッシュするレジストリです。GitLab CRを利用するので、registry.gitlab.comを指定します。最後にコンテナイメージをビルドする際のコンテキストパスを指定します(図21(6))。ここまで入力が終わったらSaveボタンをクリックします(図21(7))。
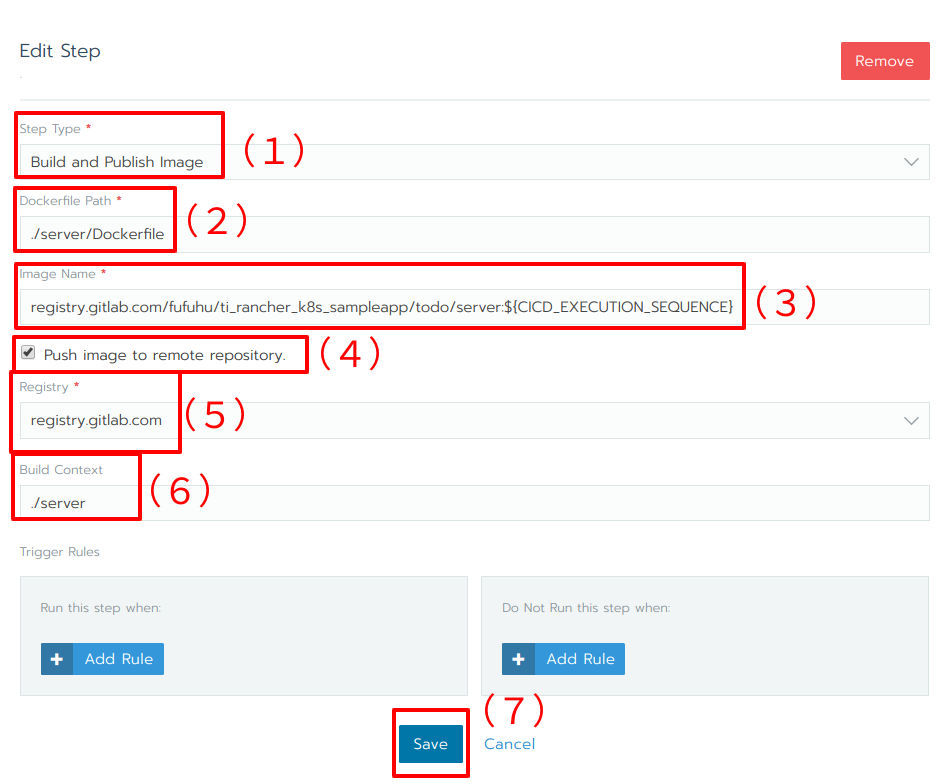
図21:ステップの詳細設定
Testステージの構築
次はTestステージです。Buildステージと同様にしてステージを追加しましょう。Testステージではサーバアプリケーションコードのテストを実行します。現行バージョンのRancher pipelineではプライベートイメージを取得してテストすることができないので、その点に配慮しつつテストの実行ステップを記述しましょう。
図22に示すステップを設定しました。
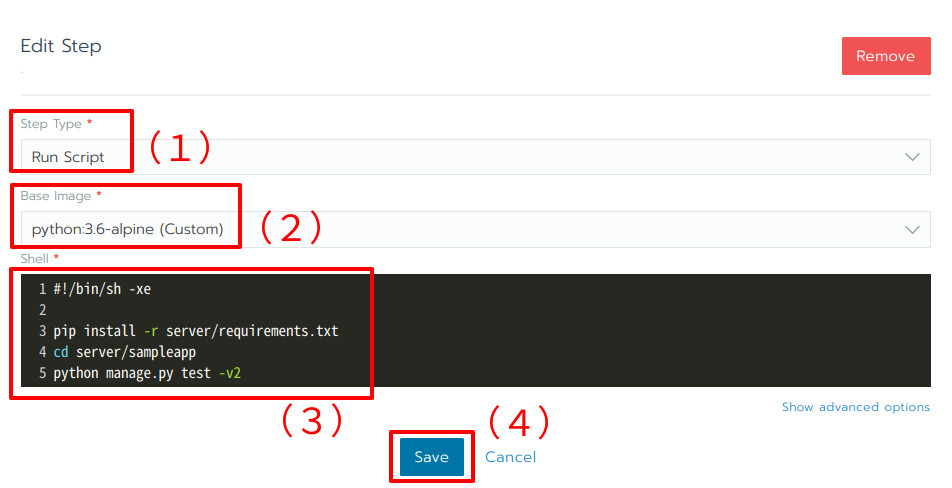
図22:サーバアプリケーションのテストを実行するステップ
コンテナの中で任意のスクリプトを実行したいので、Run Scriptを選択(図22(1))します。先ほど述べたように、プライベートリポジトリに格納されているコンテナイメージを利用することはできないので、python:3.6-alpineを指定(図22(2))しました。図22(3)にはテストを実行するためのスクリプトを設定します。ここまで完了したらSaveボタンをクリック(図22(4))しましょう。
Deployステージの構築
最後にDeployステージです。事前に定義したKubernetesのリソースマニフェスト(リスト1※4)を使って、サーバアプリケーションをデプロイします。ステージを作成したら、デプロイのためのステップを準備しましょう(図23)。
※4:secret-todoserverに指定している内容はダミーです。前回の連載の際と同様に、GitLab CRの読み取り権限を持ったアクセストークン情報が含まれています。また、ファイル中に含まれている${CICD_EXECUTION_SEQUENCE}には、Rancher Pipelineの事前定義された環境変数が入ります。詳細については、公式ドキュメント)を確認して下さい。
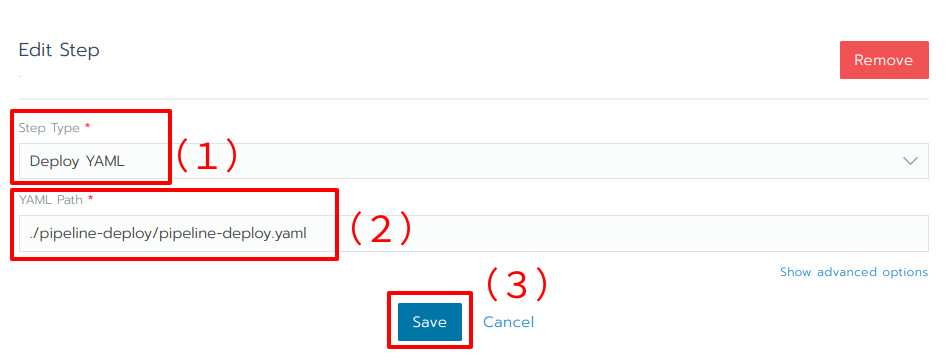
図23:Kubernetesのリソースマニフェストをデプロイするためのステップ
リスト1:事前準備しておいたk8sのリソースマニフェストファイル(pipeline-deploy/pipeline-deploy.yaml)
apiVersion: v1
kind: Secret
type: kubernetes.io/dockerconfigjson
metadata:
name: secret-todoserver
data:
.dockerconfigjson: dummy
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-todoserver
labels:
app: todoserver
spec:
rules:
- host: pipelined.web.ryoma0923.work
http:
paths:
- path: /
backend:
serviceName: service-todoserver
servicePort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: service-todoserver
labels:
app: todoserver
spec:
type: ClusterIP
selector:
app: todoserver
ports:
- name: http
port: 8000
protocol: TCP
targetPort: 8000
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-todoserver
labels:
app: todoserver
spec:
replicas: 1
selector:
matchLabels:
app: todoserver
template:
metadata:
labels:
app: todoserver
spec:
containers:
- name: todoserver
image: ${CICD_IMAGE}:${CICD_EXECUTION_SEQUENCE}
imagePullSecrets:
- name: secret-todoserver
最終的に完成したパイプラインは図24のようになりました。
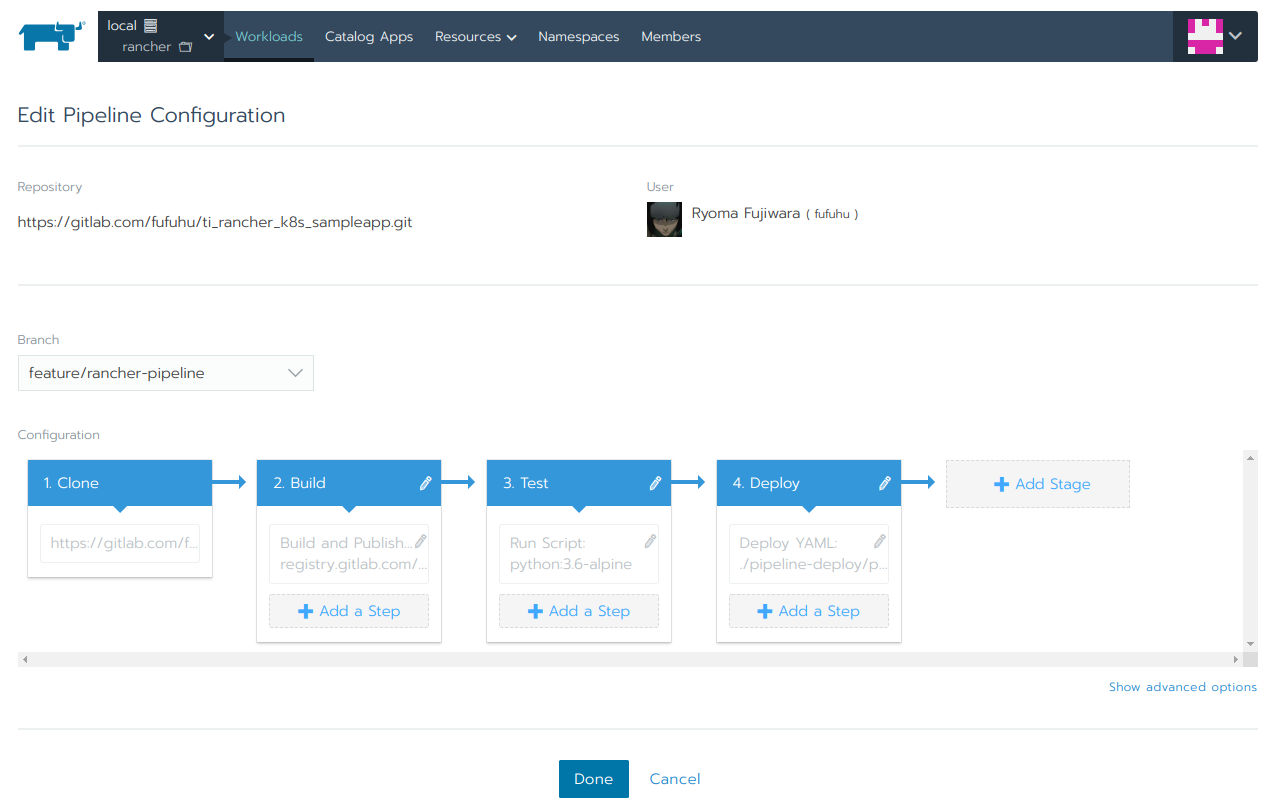
図24:完成したパイプライン
Doneボタンをクリックして保管しましょう。この際に、変更内容をダウンロードするか、GitLabのリポジトリにプッシュするかを聞かれるので、後者を選択しましょう。.rancher-pipeline.ymlが当該リポジトリの図17(1)で選択したブランチにプッシュされます。
試しに、作成したパイプラインを実行してみましょう。コードの変更などをプッシュすれば自動で実行されますが、現時点は特に変更したい内容がないので、パイプラインの実行のためにRunをクリック(図25 赤枠)します。
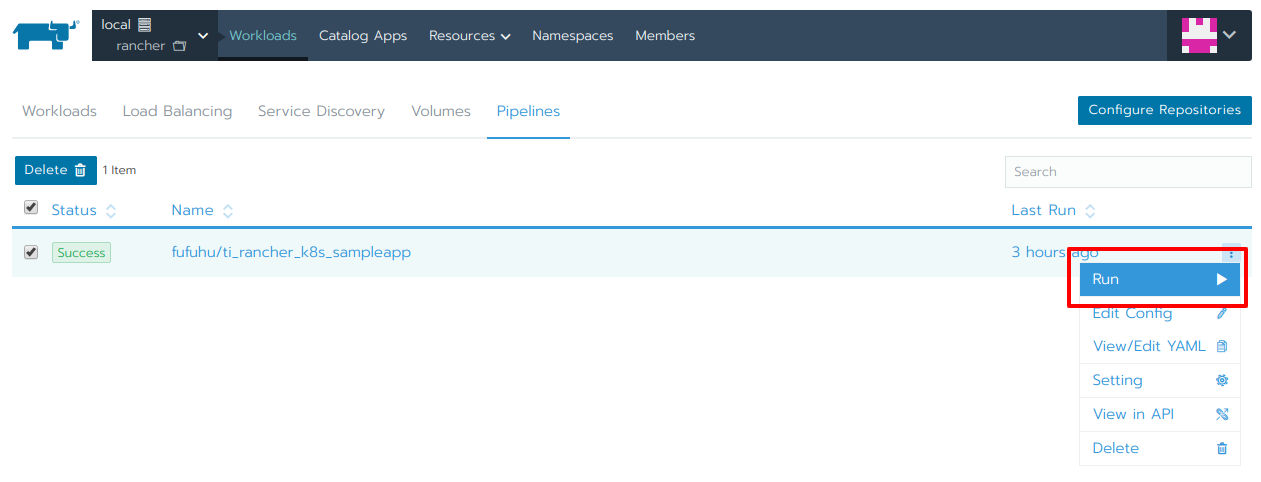
図25:パイプラインの実行
パイプラインの実行結果を確認するためにパイプラインの詳細を見ていきましょう。図25のName列の値をクリックすることで、任意のパイプラインの実行結果一覧画面に移動できます。パイプラインの実行結果一覧画面(図26)では、パイプライン実行の成否、対象となったブランチ、実行の対象となったコミットなどが表示されます。

図26:パイプラインの実行結果一覧
では、個々のパイプラインの実行結果を見てみましょう(図26のRun列の#~のリンクをクリックします。)。パイプラインの実行結果詳細(図27)では、図26の情報に加えてPipelineを構成する各Stageおよびその中に含まれるStepの実行結果が表示されます。
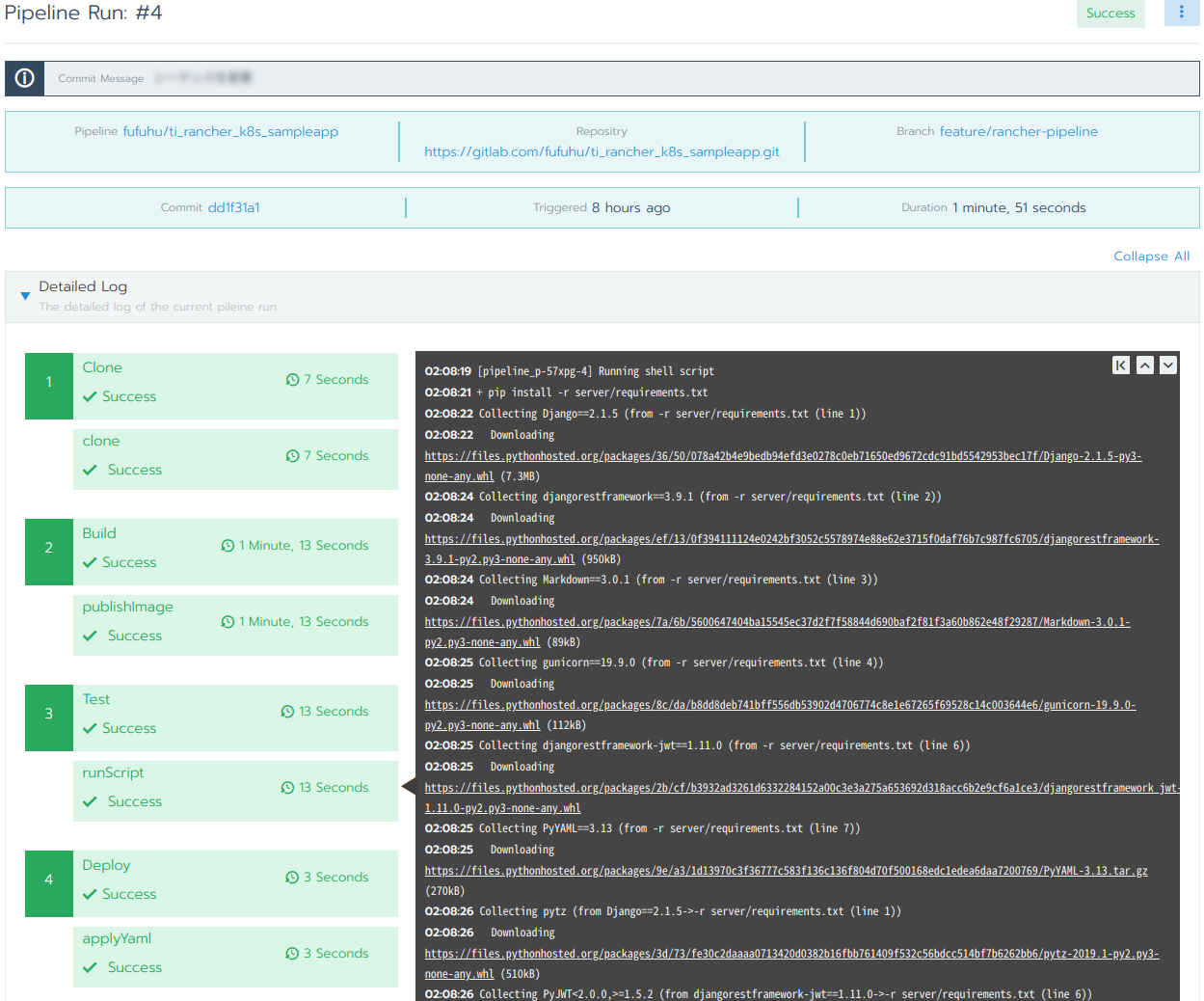
図27:パイプラインの実行結果詳細
図27を見る限りはパイプラインの実行は成功しているようなので、リスト1記載のリソースが正しくデプロイされ、動作しているかを確認しましょう(図28-30 赤枠)。
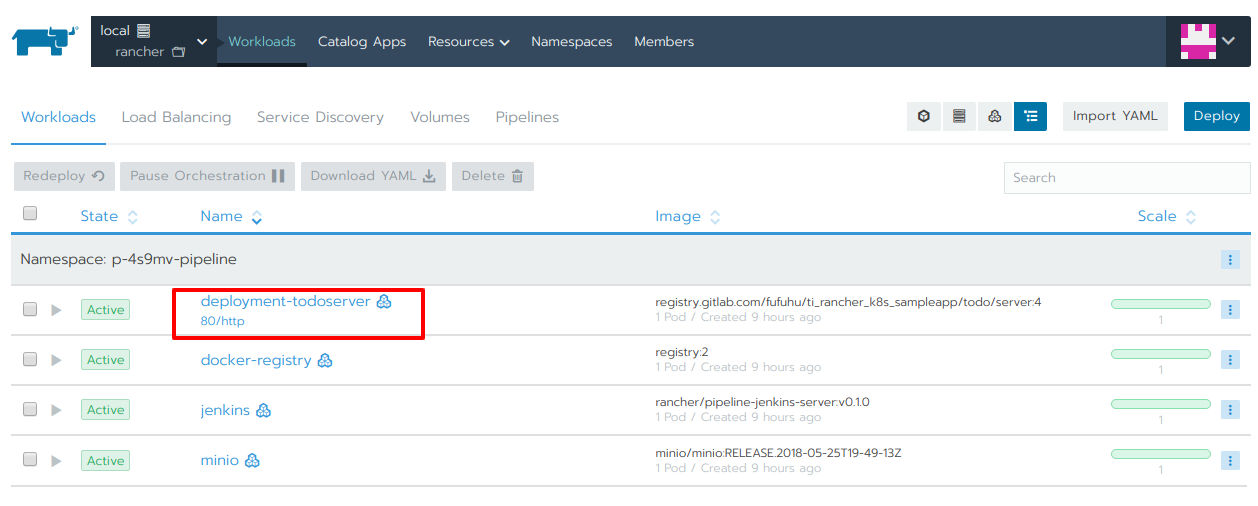
図28:Deploymentのようす
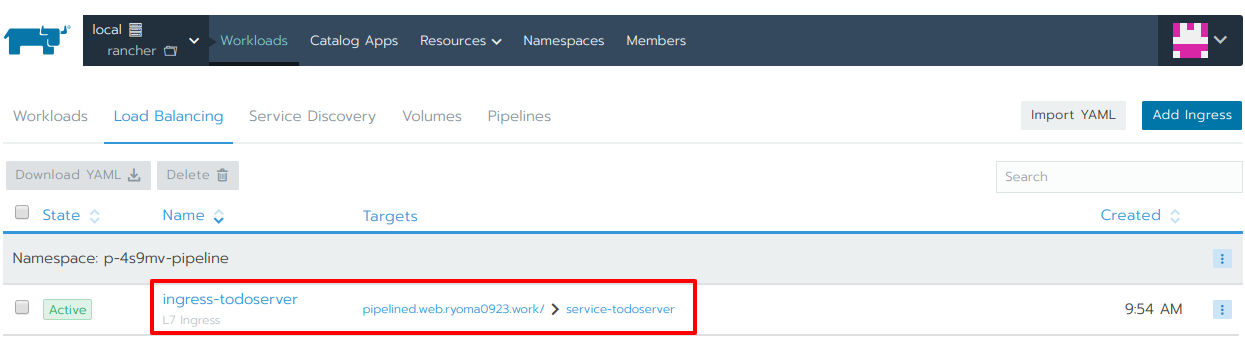
図29:Ingressのようす
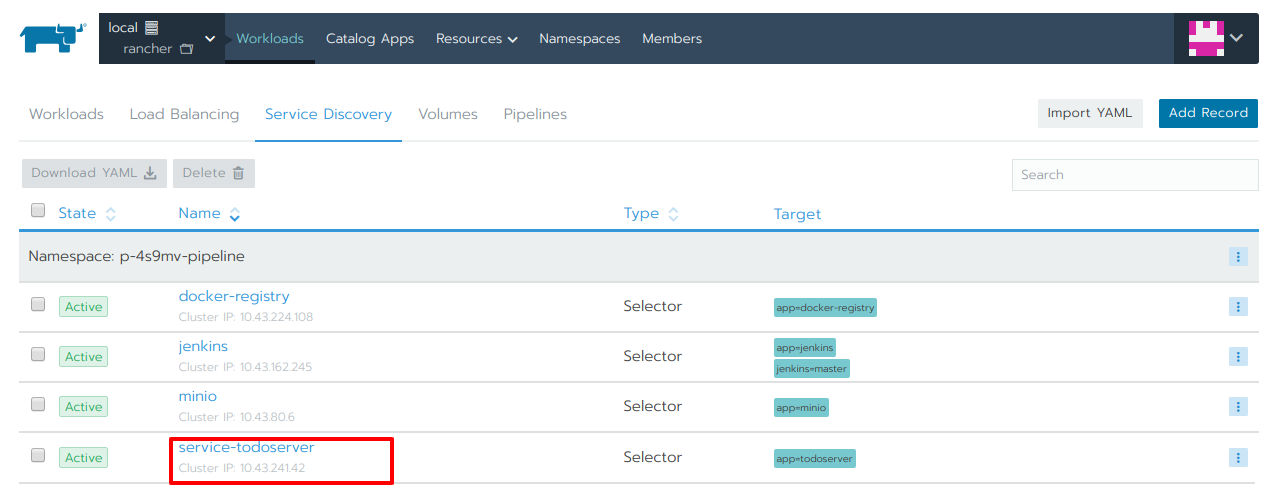
図30:Serviceのようす
確認した限りでは、リソースは正しく設定されているようです。では、最後にブラウザで前回作成したPingPong APIにアクセスできるかを確認してみましょう。コード1のIngressの設定に沿って、Webブラウザで@<b>{http://pipelined.web.ryoma0923.work/api/pingにアクセスした結果が図31です。
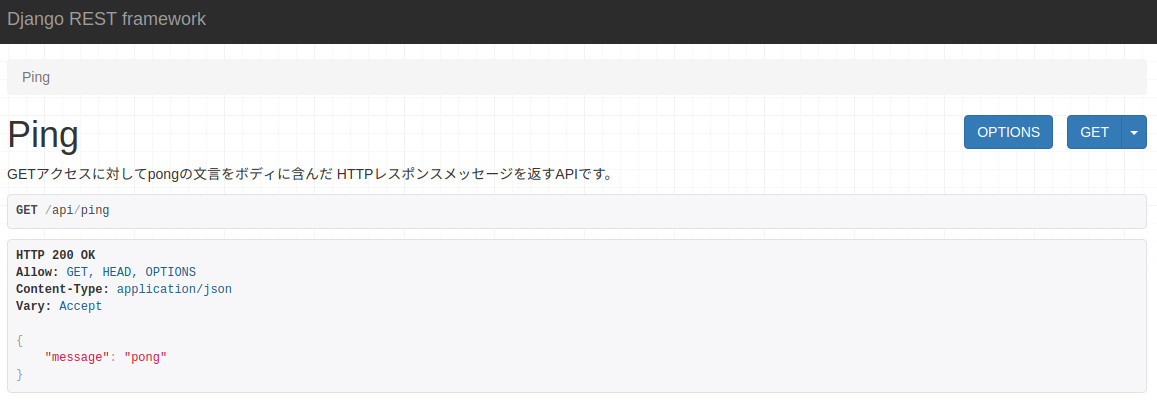
図31:新しく立ち上げたサーバアプリケーションにブラウザでアクセスした結果
これで前回作成したGitLab CIを用いたパイプラインと同等のものを準備しつつ、CDについても実現することができました。
まとめ
今回はRancher Pipelineを用いてアプリケーションのCI/CDパイプラインを記述する方法について解説しました。GUIを用いた直感的な操作で、インタラクティブにパイプラインを構成できることがわかっていただけたかと思います。なお、今回はRancherのバージョン2.1を題材として解説しています。冒頭でも解説したとおり、2019年4月にリリースされたバージョン2.2では、パイプラインの中でカタログを公開したり、カタログアプリケーションをデプロイしたりといった機能が追加され、ますます機能が充実しています。
また、今回は解説していませんが、gitリポジトリでタグ付けされたタイミングのみパイプラインを実行(デフォルトはコードがプッシュされるたび)するように設定することも可能になりました。これを活かして、GitLab CIでイメージをビルド&テストし、テストをパスしたらタグ付けし、Rancher Pipelineで自動デプロイ(CD)というように、GitLab CIとRancher Pipelineのそれぞれが得意とする部分を組み合わせて、上手く役割分担することもできるかもしれません。
本連載の筆者(藤原)の担当分は今回までとなります。実際の開発プロセスの中でRancherをどう活用するかをイメージしてもらえたのであれば幸いです。次回からは、LINEの西脇さんの執筆で、Rancherの内部構造についてDeep Diveし、深く理解していく内容となります。

市川 豊、藤原 涼馬、西脇 雄基 著 |
RancherによるKubernetes活用完全ガイドこの連載が書籍になりました! 本書は、インプレスの“オープンソース技術の実践活用メディア”Think ITの連載記事『 マルチクラウド時代の最強コンビ RancherによるKubernetes活用ガイド』の内容を元に、未公開原稿を大幅加筆して書籍化したものです。Kubernetesクラスタを管理するプラットフォームRancherを用いて、Kubernetesを活用する方法を紹介します。
|













