KubeCon China 2025、ByteDanceが開発するAIBrixのセッションを紹介

KubeCon+CloudNativeCon China 2025から、ByteDanceが開発するAIBrixを解説するセッションを紹介する。AIBrixはPyTorch FoundationでホストされているvLLMプロジェクトの一部として、オープンソースとして開発が進められている。vLLM自体はUniversity of California, Berkeley(UCB)で開発され、PyTorch Foundationに寄贈されている大規模言語モデルを高速実行するためのライブラリーだ。AIBrixはByteDanceが開発し、オープンソースとして公開したという経緯があるため、ByteDanceがAIBrixを解説するというのは自然な流れだろう。ちなみにオープンソースをビジネスとして成功させたRed Hatが、2025年5月に開催したRed Hat SummitでRed Hat AIとして発表したエンタープライズ向けのプロダクトの大元となったオープンソース版がvLLMである。

Kubernetes上のvLLM実行のためのコントロールプレーンAIBrixを解説
プレゼンテーションを行ったのはByteDanceのエンジニアリングチームのトップ、Liguang Xie氏とJiaxin Shan氏だ。約30分という長さのセッションではスライドに多くの引用文献が記載されており、ByteDanceがアカデミアも含めて広く研究と調査を実施していることがわかるセッションとなっている。

プレゼンテーションを行うXie氏(左)とShan氏(右)
●動画:Introducing AIBrix: Cost-Effective and Scalable Kubernetes Control Plane for VLLM
セッションの冒頭でそのトークンの処理の基本的な動作についてXie氏が解説していることの背景は、大規模言語モデルの内部で行われるトークンの処理(PrefillとDecode)において推論処理の中間結果を保存するKV Cacheを効率的に使うことの重要さだ。vLLMはKV Cacheを効率利用するために開発されたPagedAttentionというメカニズムが導入されている。PagedAttentionという発明は、オペレーティングシステムのキャッシュメモリの動作を参考に、UCBのエンジニアによって開発されたというのが始まりだ。vLLMのブログにその動作や背景などが解説されているので参考にして欲しい。
●ブログ:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
Xie氏はクローズドなAIからオープンソースによるAIが徐々に追い付いて来ていることをスタンフォード大の調査結果から引用して説明。
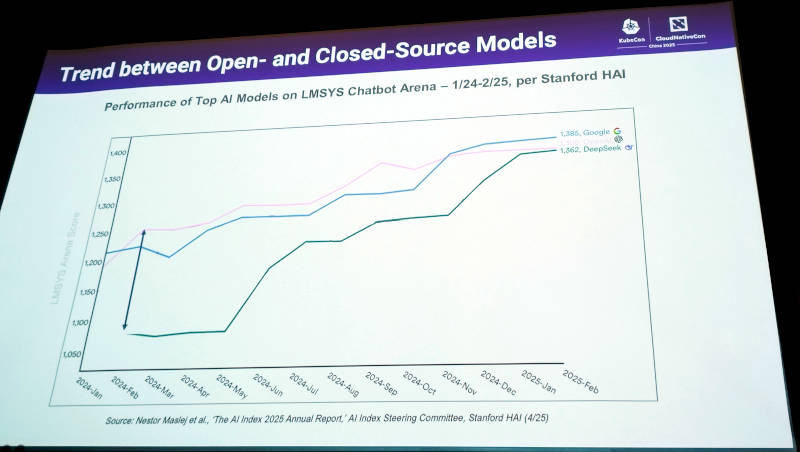
クローズドなAIとオープンソースのAIの性能差がなくなりつつある
また生成AIに関わるデベロッパーの数の爆発的な増加、Googleが毎月処理しているトークン処理の増加からエンタープライズ企業においても生成AI活用が進んでいるであろうことを紹介した。その上でセルフホストによるLLMの実行をスケーラブルに行う必要性が増加することを示し、AIBrixがそのためのツールとして利用可能であるというこのスライド以降に繋がる解説を行った。
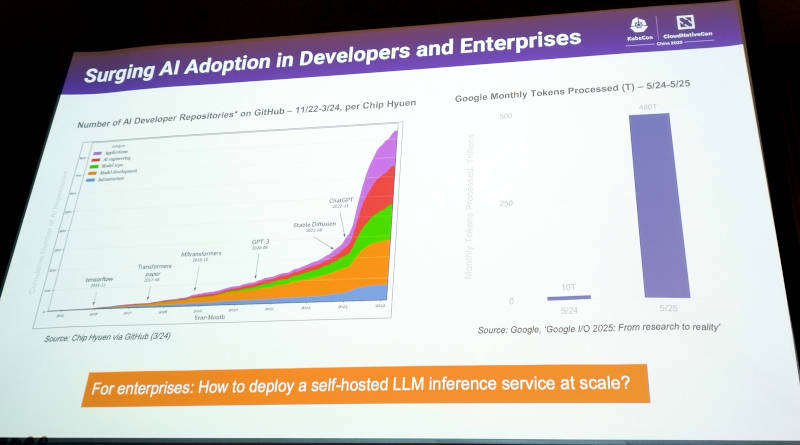
生成AIがエンタープライズ向けに必要となる時代がやってきた
AIBrixについてはオーバービューとして1枚のスライドで解説。AIBrixはクラウドネイティブであり、LLMの推論実行のライフサイクルを管理するインフラストラクチャーのためのプラットフォームとしてByteDanceで開発され、vLLMプロジェクトの一部として寄贈、公開されたと説明している。

AIBrixを1枚で紹介
より詳細に解説したのが次のスライドだ。ここではOpenAI互換のAPIから下位のレイヤーまで含めて解説している。API Gatewayはトークンの送り先をGPUの機種相違を意識してルーティング、モデルサービスでは複数のモデルの管理、vLLMが実行される推論レイヤーではKubernetesで管理されるコンテナのオートスケーリングやマルチノードでのPrefillとDecodeの配置、KV Cacheレイヤーでは分散ストレージの管理など多くのコンポーネントが含まれていることがわかる。
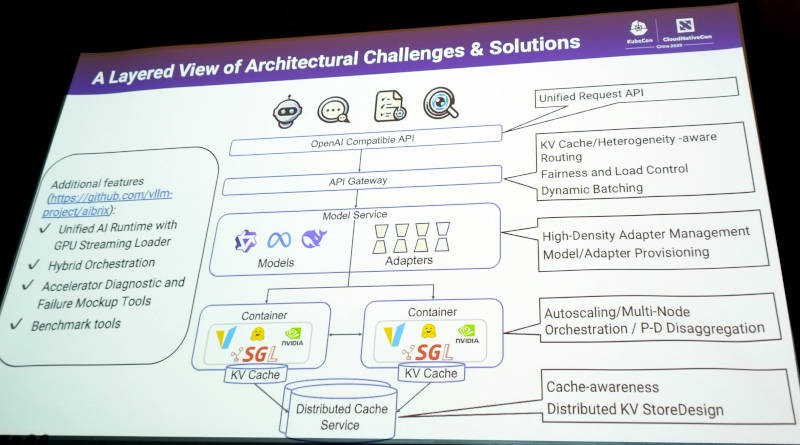
AIBrixのシステムアーキテクチャーをさらに詳しく解説
Xie氏は前のスライドをさらに詳細に分解したアーキテクチャー図を使ってAIBrixを解説。データプレーン、コントロールプレーンに分けてAIBrixを構成するモジュールを見せた。コンテナ(Pod)にvLLMが推論エンジンとして構成され、そこにベースとなるモデルとLoRAによるチューニング、サイドカーとしてモデルローダー、オブザーバビリティのためのランタイムエージェントやWatchdogなどが加えられ、それがA100やL40と言った異機種GPUにスケジューリングされ、中間結果であるKV Cacheは複数のノードに分散されて実装されるという仕組みだ。実際には「これは細か過ぎて読めないかもしれないけどね」とコメントしながらも真面目に参加者に情報提供を行っていることを感じた瞬間であった。
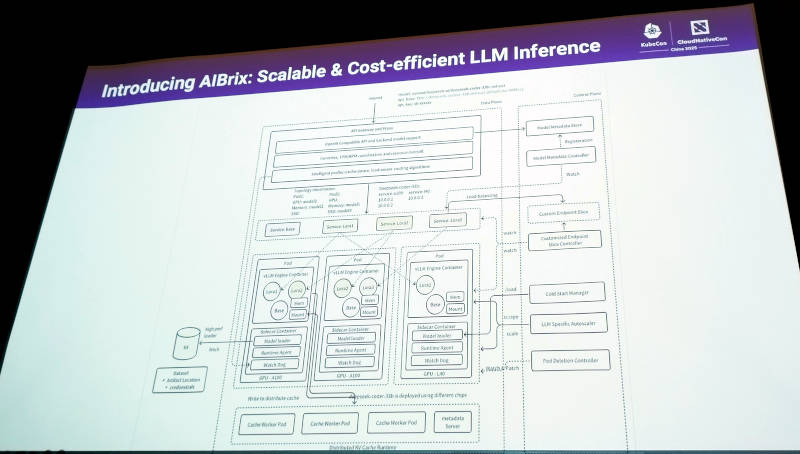
より詳細なAIBrixのアーキテクチャー図
次にAIBrixがオープンソースになったことをブログ記事の引用を使って紹介。他にもGoogleやRed Hatと一緒にマルチノードでの推論を実装するLeaderWorkerSet(LWS)を実装した例やAWSのEKSでAIBrixに関するワークショップが行われたことなどを紹介した。AIBrixに関するブログは以下を参照されたい。複数ノードで推論を実装するLeaderWorkerSet(LWS)はこのセッション以外でも何度か言及されており、マルチノードでの推論が中国では熱い議論の対象になっていることがわかる。
●vLLMのブログ:Introducing AIBrix: A Scalable, Cost-Effective Control Plane for vLLM
AIBrixに関するブログ記事などを紹介
他にもGoogleのClayton Coleman氏のコメントなどもスライドとして紹介され、vLLMのプロジェクトとして生成AIについて先進的な多くのベンダーに支持されていることを見せた。

AIBrixのリリースの過去を振り返る
このスライドでは2024年10月の初期バージョンである0.1.0から2025年6月の0.4.0までの間にどのような機能拡張が行われてきたのかを紹介。オートスケーリングからリクエストのルーティングに始まり、2番目のリリースですでに分散KV Cacheが実装されていることがわかる。そして最新の0.4.0ではマルチテナンシー実装が予定されている。Kubernetesの実装においても中国企業がマルチテナンシーを最も早く手掛けていたことから、中国企業においてはマルチノード、マルチクラスターと同様にマルチテナンシーが重要な要件であることが見て取れる。
ここからはオートスケーリングについてさまざまな問題点を挙げて解説。またEnvoyを使ったGatewayにおいてルーティングの方法などについても例を挙げて説明を行った。
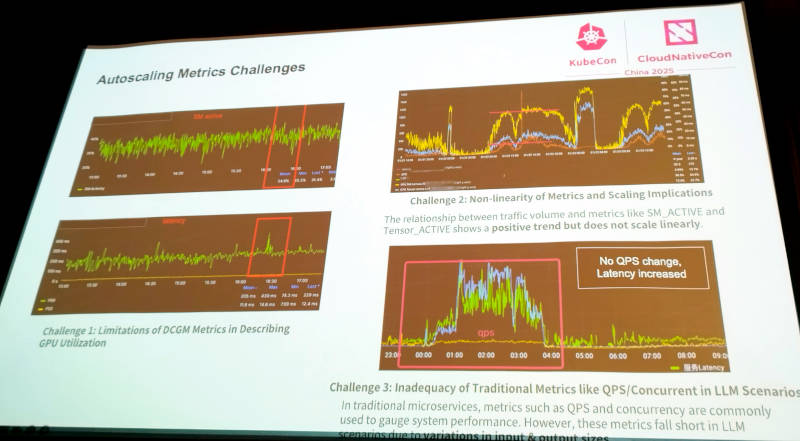
オートスケーリングにおける問題点を紹介
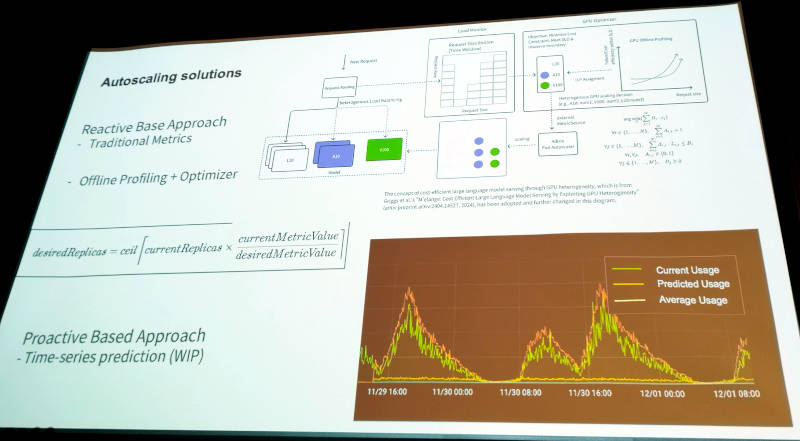
オートスケーリングにおけるスケジューリングのアプローチを紹介
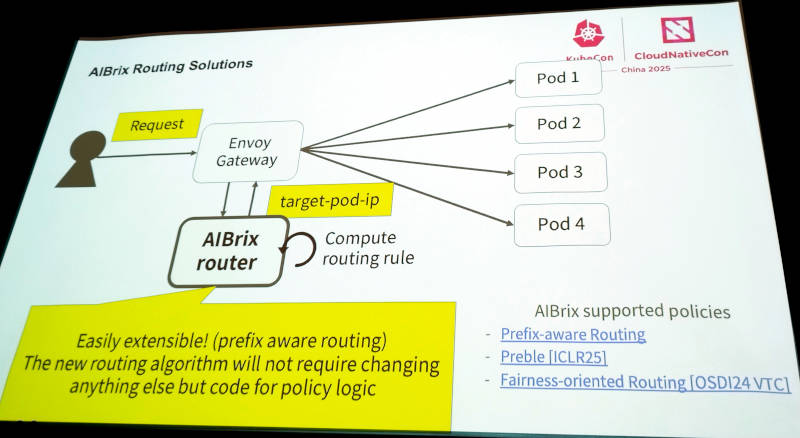
Envoyを使ってどのPodにリクエストを送るのかをPrefixを利用して判断するルーティング
またマルチノードでKV Cacheを共有する方法についても、MicrosoftとUniversity of Washingtonによる共同研究論文やUniversity of Edinburghで研究発表されたServerless LLMなどの論文を紹介して複数の実装例があることを紹介。ByteDanceが自社内でのソフトウェア開発のためにアカデミアの論文を多数読み込んで研究していることがわかるスライドとなった。
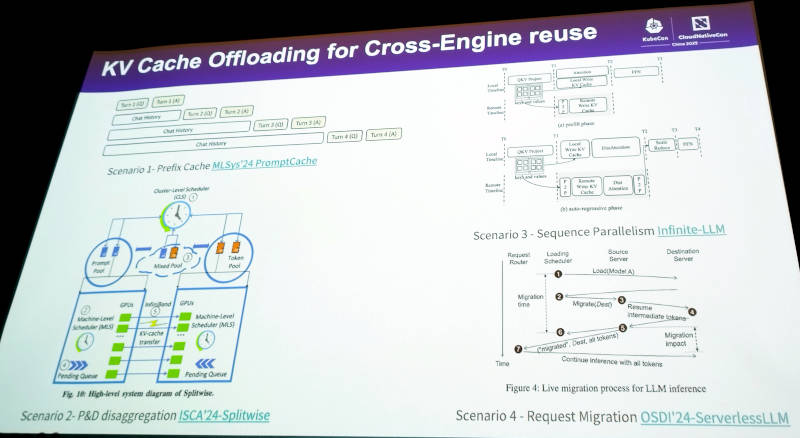
分散KV Cache実装のために複数の研究論文を参考にしていることがわかる

単一ノードにおけるKV Cacheから複数ノードでの分散KV Cacheに進化していくようすを図式化
ここではGPUのメモリーを使ったキャッシュからキャッシュサーバーを介して複数ノードに実装されていく場合のアーキテクチャーを解説している。
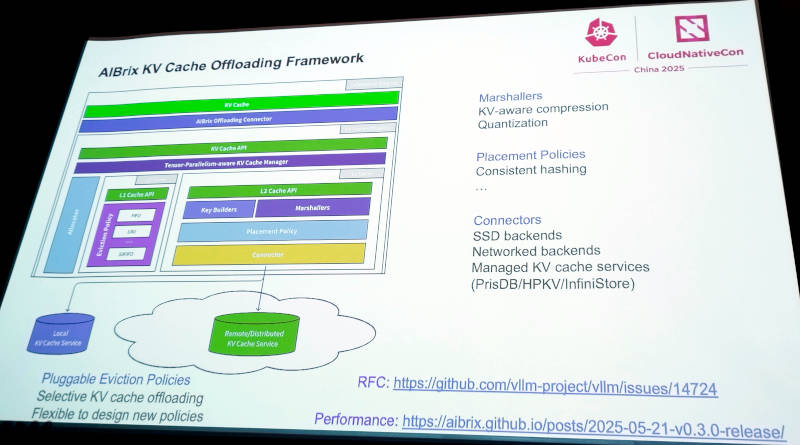
AIBrixにおける分散キャッシュの実装の紹介
この分散KV CacheについてはvLLMのGitHubリポジトリでRFCとして提案がされている。
●参考:https://github.com/vllm-project/vllm/issues/14724
キャッシュアクセスの高速化のための必須な要件として、分散KV Cacheの実装方法についてもこうしてGitHub上で英語で公開されているというところにByteDanceのオープンソースに対する本気度を感じられた。
さらにそれをKubernetes上でオーケストレーションする部分に関しても、ByteDanceのGitHubページで公開されている。
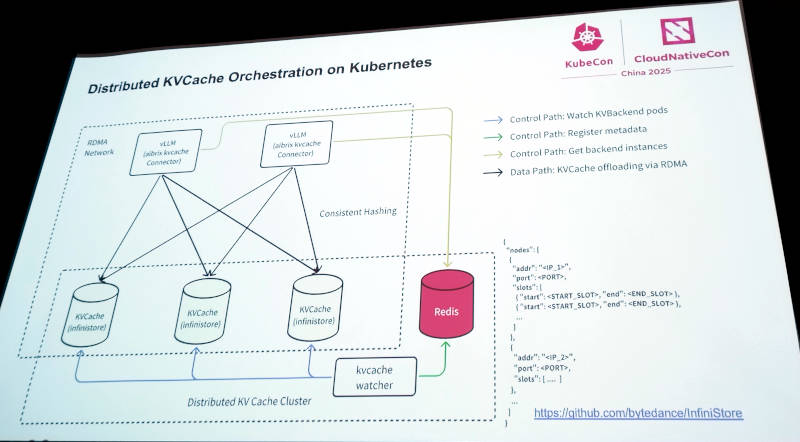
分散KV CacheをKubernetes上でオーケストレーション
●参考:https://github.com/bytedance/InfiniStore
冒頭で短く解説されたLLMのトークン処理、PrefillとDecodeについて分散する形で処理を行うことで処理速度が向上することを紹介。

PrefillとDecode処理を分散して実行する方法を解説
PrefillとDecodeの分散処理について、中央集権的に行う方法とPeer-to-Peerで行う方法について解説。AIBrixではどちらの方法も選択可能であるという。
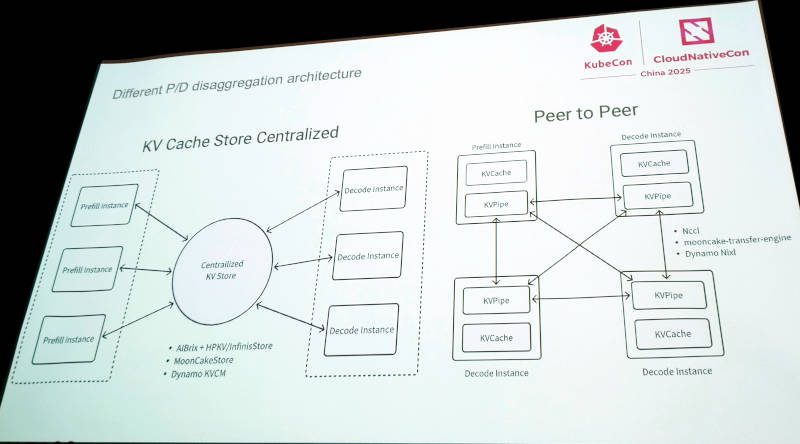
PrefillとDecodeを処理する方式を解説
AIBrixは複数の推論インスタンスにおいて、中央集権型でもPeer-to-Peer型でもPrefillとDecodeが実行できることを紹介。

最新リリース、0.4.0での機能強化ポイントを解説
このスライドでは最新リリースとして予定されている0.4.0における機能強化のポイントを整理している。PrefillとDecodeの分散処理、マルチテナンシーなどが挙げられている。ここでもマルチテナンシーを強力に意識していることがわかる。
最後にAIBrixによって大規模言語モデルをワンクリックで実装できることを紹介してセッションを終えた。
ワンクリックでモデルを実装できるデモを紹介
全体としてByteDanceがアカデミアの研究論文にも充分に注意を配りながら、vLLM配下のオープンソースプロジェクトとして成立させることを目指して活動していることが理解できるセッションとなった。KubeCon Chinaでは半分ほどのセッションが中国語による解説となっていたが、Google、Microsoft、AWSなどとも連携し中国らしさのひとつであるマルチテナンシーも視野に入れながら、英語によるプレゼンテーション、GitHubリポジトリの公開など国際的な標準に従った王道のオープンソースプロジェクトとしてAIBrixが持続していくことを目指していることを印象付ける内容となっていた。ByteDance以外のコントリビューションを増やしてどのようにAIBrixが持続していくのか、その将来を注視していきたい。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています




全文検索エンジンによるおすすめ記事
- KubeCon Europe 2025、3日目のキーノートでGoogleとByteDanceが行ったセッションを紹介
- KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
- KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
- KubeCon China:サーバーレスとマルチテナンシーのセッションに注目
- KubeCon Europe 2025、GoogleとMicrosoftがSIG発の管理用ツールを紹介
- CNDT2021、Kubernetesのマルチテナントを実装したIIJのSREが語る運用の勘所
- Kafka on KubernetesのStrimziConから新機能を解説するセッションを紹介
- KubernetesネイティブなポリシーエンジンKyverno
- KafkaにWASMモジュールを組み込んでリアルタイムで機械学習を実行するRedpandaのデモセッションを解説
- KubeCon China 2025開催、中国ベンダーによるキーノートを紹介