Kubernetesの信頼性を高める! カオスエンジニアリングツール「Krkn」

はじめに
Kubernetesをはじめとするクラウドネイティブ技術の普及により、私たちの作るシステムはますます便利になる一方で、その裏側は非常に複雑になっています。多くのサービスが連携して動く分散システムでは、個々の部品は正しくても、全体として思わぬ問題が起きることがあります。
開発段階で行うユニットテストやインテグレーションテストは重要ですが、それだけではシステム全体の複雑な動きから生じる障害をすべて事前に見つけ出すのは難しいのが現実です。
そこで役立つのが「カオスエンジニアリング」です。これはただやみくもにシステムを壊すことではありません。本番に近い環境でわざと障害(例えば、サーバーダウンやネットワークの遅延など)を引き起こし、システムがそれにどう耐えるかを観察します。
その一番の目的は、実際の障害が起きてユーザーに影響が出る前に私たちがまだ気づいていないシステムの弱点(いわゆる「未知の未知」)を先に見つけ出し、改善することにあります。この実験を通して「障害が起きたときにアラートが機能するか」「自動復旧の仕組みは期待通りに動くか」といったことを実際に試し、自分たちのシステムに対する信頼性を高めていくことができます。
この記事では、Kubernetes環境で使いやすいカオスエンジニアリングツールの「Krkn」に焦点を当て、その基本的な考え方から仕組み、具体的な使い方までを分かりやすく解説していきます。
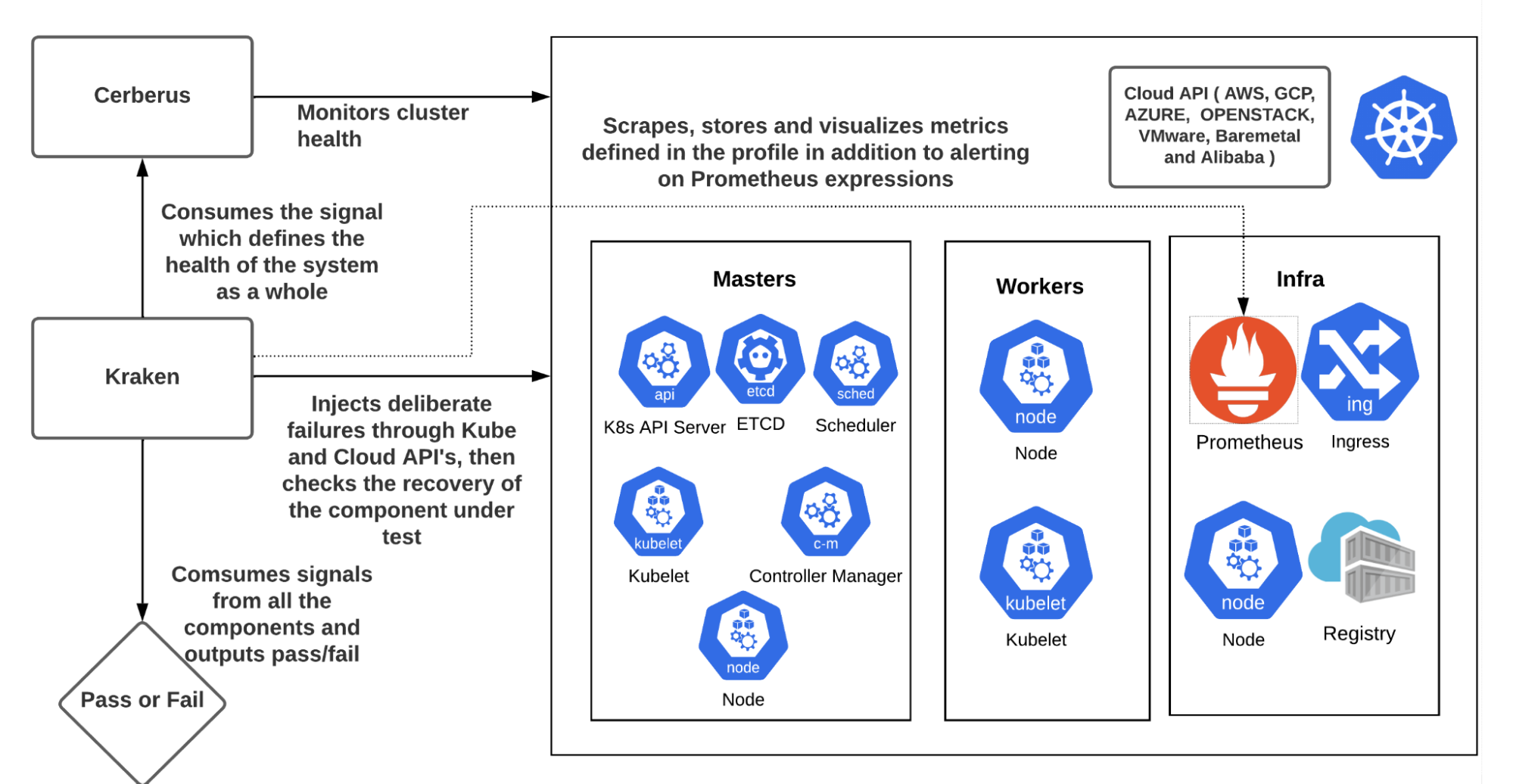
Krknとは
KrknはRed Hatによって開発され現在はCloud Native Computing Foundation(CNCF)のサンドボックスプロジェクトとしてホストされている、オープンソースのカオスエンジニアリングツールです。その主な目的はKubernetesクラスタとその上で動作するアプリケーションに意図的に障害を注入し、システムの回復性とパフォーマンスを検証・向上させることにあります。
このツールは主に、次のような役割を持つエンジニアを対象として設計されています。
- サイトリライアビリティエンジニア(SRE): Kubernetesプラットフォームと、その上でホストされるアプリケーションの信頼性向上を目指す
- 開発者・エンジニア: 障害シナリオ下におけるアプリケーションのパフォーマンスと堅牢性の向上に焦点を当てる
- Kubernetes管理者: オンボードされたサービスがベストプラクティスに準拠し、長時間の停止を防ぐことに責任を持つ
Krknの主な特徴
Krknは、Kubernetesにおけるカオスエンジニアリングを実践する上で、多くの強力な特徴を備えています。
- シグナリング
CI実行中や外部ジョブにおいて、Krknの実行を一時停止または完全に停止させるための機能。これにより、クラスターの負荷テストとKrknの実行タイミングを同期できる - パフォーマンスモニタリング
Krknのカオスシナリオがクラスターの各コンポーネントに与える影響を監視し、ボトルネックを特定する。障害注入中および注入後のクラスターの回復力とパフォーマンスを確認することが重要 - SLO検証
PromQLを使用してカオス実行中および実行後にサービスレベル目標(SLO)を検証する。メトリクスに基づいて異常を検知し、深刻度に応じてアラートを発したりエラーで終了したりできる。これにより、テストの合否判定や異常の検出が可能 - ヘルスチェック
アプリケーションの可用性とパフォーマンスに対するカオスシナリオの影響をリアルタイムで可視化。定義された間隔で指定されたURLを定期的にチェックし、結果をテレメトリに記録する - テレメトリ
Krknの実行終了時にクラスター構成と実行されたシナリオに関する基本的な詳細情報を収集・表示する。AWS S3バケットまたはElasticsearchにテレメトリデータを保存することも可能 - OCM/ACM連携
「Open Cluster Management(OCM)」および「Red Hat Advanced Cluster Management for Kubernetes (ACM)」で管理されているクラスターに対して、ManagedCluster Scenariosを通じて障害を注入することをサポートする
この記事ではデモを行いながら、次のような機能について紹介していきます。
- Kubernetesネイティブな設計
KrknはKubernetes環境に特化して作られており、Pod、Node、NamespaceといったKubernetesの基本的なリソースに対する障害シナリオを豊富にサポート。これにより、Kubernetes上で発生しうる様々な問題をリアルにシミュレートできる - 柔軟なカオスシナリオのカスタマイズ
ユーザーはYAML形式の設定ファイルで独自のカオスシナリオを定義できる。特定のアプリケーションやインフラの特性に合わせた、きめ細やかなストレステストが可能 - クラウドとKubernetesの両シナリオに対応
AWS、Azure、GCPといったクラウドインフラに特有の障害(例:VMインスタンスの停止)と、Kubernetesネイティブな障害(例:Podの削除)の両方をサポートしており、ハイブリッドな障害シナリオを構築できる - Chaos Recommenderによるシナリオ提案
テレメトリデータを分析してアプリケーションに負荷がかかっている箇所などを特定し、最も影響を与えうる効果的なカオスシナリオを提案してくれる「Chaos Recommender」というユニークな機能を備える
😚Krknと連携するKubernetes監視ツールの「Cerberus」についてはこの記事では扱わず、Krkn単体での動作を紹介します。
Krknがサポートするカオスシナリオ
Krknはアプリケーションからインフラ層まで、多岐にわたる障害をシミュレートできます。以下に代表的なシナリオを挙げます。
- Pod/コンテナレベルの障害
- Podのランダムな削除、再起動
- コンテナへの障害注入
- Nodeレベルの障害
- Nodeの停止、再起動
- Nodeの電源断シミュレーション
- Nodeリソース(CPU/メモリ)の枯渇
- ネットワーク障害
- PodやNodeレベルでのネットワーク遅延、パケットロス
- ストレージ障害
- 永続ボリューム(PV)の容量枯渇
- アプリケーション/サービスレベルの障害
- 特定のアプリケーションプロセスの停止
- 依存する外部サービスの無効化
- クラウドプロバイダー特有の障害
- AWS、Azure、GCPにおけるVMインスタンスの停止・終了
対応しているシナリオの一覧は、こちらのドキュメントに記載されています。
Krknを使ってみよう
それでは、実際にKrknをどのように利用するのか、その基本的な流れを見ていきましょう。
1. 準備
まず、カオス実験の対象となる実行中のKubernetesクラスタが必要です。今回は以下の環境でデモで使用します。
- GKE Standard (1.33.2-gke.1240000)
- Krkn v4.0.5
2. インストールと設定
ドキュメントに従って準備を行います。
$ git clone <https://github.com/Krkn-chaos/Krkn.git> --branch v4.0.5 $ cd Krkn $ python3 -m venv chaos $ source chaos/bin/activate $ pip install -r requirements.txt
リポジトリ内のconfig/config_kubernetes.yamlを確認し、環境に応じて編集します。ここでは次のようにしました。設定可能な項目についてはドキュメントを参照してください。
kraken:
distribution: kubernetes
kubeconfig_path: ~/.kube/config
exit_on_failure: False
port: 8081
publish_kraken_status: True
signal_state: RUN
chaos_scenarios:
- pod_disruption_scenarios:
- scenarios/kube/pod.yml
cerberus:
cerberus_enabled: False
performance_monitoring:
prometheus_url: localhost:9090 # デモ環境ではManaged Service for Prometheusへのプロキシ
enable_alerts: False
check_critical_alerts: False
tunings:
wait_duration: 30
iterations: 1
daemon_mode: False
health_checks:
interval: 2
config:
- url: <ここにヘルスチェック対象を記載します。デモではLBのIPアドレスを記載します>
bearer_token:
auth:
exit_on_failure: False
verify_url: False
3. シナリオの実行(デモ)
ここでは、実際にKrknを使ってPod障害シナリオを実行するデモを行います。簡単な設定を使って使用する流れを確認していきます。
pod_disruption_scenarios
始めに、Podのkillシナリオを指定して動作を確認してみます。手順2でconfigファイルにscenarios/kube/pod.ymlを指定しており、これを実行します。pod.ymlは次のような設定になっています。フィールドについてはドキュメント上で全て説明されていないため、ソースコードを確認したほうが良さそうです。
# yaml-language-server: $schema=../plugin.schema.json
- id: kill-pods
config:
name_pattern: ^nginx-.*$ # 対象となるPodの名前パターン
namespace_pattern: ^default$ # 対象となるPodの名前パターン
kill: 1 # killするPodの数
Krkn_pod_recovery_time: 120
対象となるnginxのPodを作成しておきます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 250m
memory: 500Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
準備ができたので、Krknを実行してみます。実行しているシナリオの情報や影響を受けるリソースの情報が出力されながらテストが進行していきます。
$ python3 run_kraken.py --config config/config_kubernetes.yaml
_ _
| | ___ __ __ _| | _____ _ __
| |/ / '__/ _` | |/ / _ \\ '_ \\
| <| | | (_| | < __/ | | |
|_|\\_\\_| \\__,_|_|\\_\\___|_| |_|
2025-08-29 10:24:29,843 [INFO] Starting kraken
...<出力省略>...
2025-08-29 10:24:31,928 [INFO] Executing scenarios for iteration 0
2025-08-29 10:24:31,928 [INFO] connection set up
127.0.0.1 - - [29/Aug/2025 10:24:31] "GET / HTTP/1.1" 200 -
2025-08-29 10:24:31,932 [INFO] response RUN
2025-08-29 10:24:31,936 [INFO] Running PodDisruptionScenarioPlugin: ['pod_disruption_scenarios'] -> scenarios/kube/pod.yml
2025-08-29 10:24:32,141 [INFO] waiting up to 120 seconds for pod recovery, pod name pattern: ^nginx-.*$ namespace pattern: ^default$
2025-08-29 10:24:32,320 [INFO] ('nginx-deployment-77f7cbd5d8-ssmj8', 'default')
2025-08-29 10:24:32,320 [INFO] Deleting pod nginx-deployment-77f7cbd5d8-ssmj8
2025-08-29 10:24:43,895 [INFO] wating 10 before running the next scenario
2025-08-29 10:24:54,085 [INFO] collecting Kubernetes cluster metadata....
...<出力省略>...
設定ファイルにヘルスチェックの設定をしている場合はヘルスチェックのログも出力されるため、テストによりサービスアクセスに影響があったのかを確認できます。例えば、次の出力からは4秒間500エラーが返されていたことが分かります。
...出力部分抜粋...
"timestamp": "2025-08-29T10:26:48Z",
"health_checks": [
{
"url": "<http://x.x.x.x:80>",
"status": false,
"status_code": "200",
"start_timestamp": "2025-08-29T10:26:49.727996",
"end_timestamp": "2025-08-29T10:26:51.734376",
"duration": 2.00638
},
{
"url": "<http://x.x.x.x:80>",
"status": false,
"status_code": "500",
"start_timestamp": "2025-08-29T10:26:53.740337",
"end_timestamp": "2025-08-29T10:26:57.760655",
"duration": 4.020318
},
{
"url": "<http://x.x.x.x:80>",
"status": true,
"status_code": 200,
"start_timestamp": "2025-08-29T10:26:59.773545",
"end_timestamp": "2025-08-29T10:27:13.843695",
"duration": 14.07015
}
],
node_scenarios
次に、ノードに対してイベントを発生してみます。特定のゾーンのノードを指定して停止するイベントです。リポジトリのscenarios/openshift/gcp_node_scenarios.ymlを参考に次のように変更します。ゾーンbのノードが再起動されることを期待します。
node_scenarios:
- actions:
- node_reboot_scenario
node_name:
label_selector: topology.kubernetes.io/zone=asia-northeast1-b
instance_count: 1
timeout: 120
cloud_type: gcp
parallel: true
kube_check: true
設定ファイルを更新して、シナリオを指定します。
kraken:
distribution: kubernetes # Distribution can be kubernetes or openshift
kubeconfig_path: ~/.kube/config # Path to kubeconfig
exit_on_failure: False # Exit when a post action scenario fails
port: 8081
publish_kraken_status: True # Can be accessed at <http://0.0.0.0:8081>>
signal_state: RUN # Will wait for the RUN signal when set to PAUSE before running the scenarios, refer docs/signal.md for more details
signal_address: 0.0.0.0 # Signal listening address
chaos_scenarios: # List of policies/chaos scenarios to load
- node_scenarios:
- scenarios/openshift/gcp_node_scenarios.yml
実行前にノードの状態を確認します。3つのゾーンの1つずつノードがあることが確認できます。
$ kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\\t"}{.metadata.labels.topology\\.gke\\.io/zone}{"\\n"}{end}'
gke-cluster-1-default-pool-0b86d23b-twk9 asia-northeast1-a
gke-cluster-1-default-pool-a9ae1baf-30xg asia-northeast1-b
gke-cluster-1-default-pool-f11c1613-jpl8 asia-northeast1-c
シナリオを実行します。指定したasia-northeast1-bのノードにイベントが発生していることが分かります。
$ python3 run_kraken.py --config config/config_kubernetes.yaml
...<出力省略>...
{
"telemetry": {
"scenarios": [
{
"start_timestamp": 1756465020,
"end_timestamp": 1756465147,
"scenario": "scenarios/openshift/gcp_node_scenarios.yml",
"scenario_type": "node_scenarios",
"exit_status": 0,
"parameters_base64": "",
"parameters": {
"node_scenarios": [
{
"actions": [
"node_reboot_scenario"
],
"cloud_type": "gcp",
"instance_count": 1,
"kube_check": true,
"label_selector": "topology.kubernetes.io/zone=asia-northeast1-b",
"node_name": null,
"parallel": true,
"timeout": 120
}
]
},
...
"affected_nodes": [
{
"node_name": "gke-cluster-1-default-pool-a9ae1baf-30xg", # asia-northeast1-bのノードが影響を受けたことを確認できる
"node_id": "gke-cluster-1-default-pool-a9ae1baf-30xg",
"not_ready_time": 120.04839873313904,
"ready_time": 0.16450238227844238,
"stopped_time": 0.0,
"running_time": 1.3358662128448486,
"terminating_time": 0.0
...<出力省略>...
$ kubectl get node -w NAME STATUS ROLES AGE VERSION gke-cluster-1-default-pool-0b86d23b-twk9 Ready <none> 16m v1.33.2-gke.1240000 gke-cluster-1-default-pool-a9ae1baf-30xg Ready <none> 9m27s v1.33.2-gke.1240000 gke-cluster-1-default-pool-f11c1613-jpl8 Ready <none> 16m v1.33.2-gke.1240000 gke-cluster-1-default-pool-a9ae1baf-30xg NotReady <none> 9m59s v1.33.2-gke.1240000 gke-cluster-1-default-pool-a9ae1baf-30xg NotReady <none> 10m v1.33.2-gke.1240000 gke-cluster-1-default-pool-a9ae1baf-30xg Ready <none> 10m v1.33.2-gke.1240000 gke-cluster-1-default-pool-a9ae1baf-30xg Ready <none> 10m v1.33.2-gke.1240000
他にも様々なシナリオを指定することが可能で、リポジトリにはサンプルとして複数用意されています。シナリオファイルを自分の環境に合うように編集し、実行するリストに組み込んでいくことで目的のテストを行えるようになります。
付録: Chaos Recommendation Toolについて
どのようなシナリオが適しているかを推奨してくれるツールがKrknリポジトリで提供されています。このツールはPrometheusのクエリを使用してアプリケーションを評価し、関連するテストケースを推奨します。具体的な動作の雰囲気を理解するため、簡単にデモ環境への実行結果のみ紹介します。実行方法についてはドキュメントを参照してください。
以下の出力からはapplication_outage、node_network_chaos、pod_network_chaosが推奨として挙げられました。
$ python3 utils/chaos_recommender/chaos_recommender.py -c config/recommender_config.yaml
...<出力省略>...
"analysis_outputs": [
{
"namespace": "default",
"queries": {
"cpu_query": "sum (rate (container_cpu_usage_seconds_total{image!=\\"\\", namespace=\\"default\\"}[10m])) by (pod) *1000",
"cpu_limit_query": "(sum by (pod) (kube_pod_container_resource_limits{resource=\\"cpu\\", namespace=\\"default\\"}))*1000",
"memory_query": "sum by (pod) (avg_over_time(container_memory_usage_bytes{image!=\\"\\", namespace=\\"default\\"}[10m]))",
"memory_limit_query": "sum by (pod) (kube_pod_container_resource_limits{resource=\\"memory\\", namespace=\\"default\\"}) ",
"network_query": "sum by (pod) ((avg_over_time(container_network_transmit_bytes_total{namespace=\\"default\\"}[10m])) + (avg_over_time(container_network_receive_bytes_total{namespace=\\"default\\"}[10m])))"
},
"profiling": {
"cpu_outliers": [],
"memory_outliers": [],
"network_outliers": [
"nginx-deployment-68f6b85cbb-txvg8"
]
},
"heatmap_analysis": {
"services_with_cpu_heatmap_above_threshold": [],
"services_with_mem_heatmap_above_threshold": []
},
"recommendations": {
"outliers_network_recommendations": {
"outliers_networks": [
"nginx-deployment-68f6b85cbb-txvg8"
],
"tests": [
"application_outage",
"node_network_chaos",
"pod_network_chaos"
]
}
}
}
]
}
おわりに
本記事では、Kubernetes向けのカオスエンジニアリングツール「Krkn」について紹介しました。Krknを活用することで、開発チームやSREチームはシステムの潜在的な弱点を発見し、より回復性の高い、堅牢なサービスを構築できるようになります。ぜひ、ご自身の環境でKrknを試し、カオスエンジニアリングの世界に足を踏み入れてみてください。
【参考】- GitHubリポジトリ Krkn-chaos/Krkn:https://github.com/Krkn-chaos/Krkn
- Krkn公式サイト:https://Krkn-chaos.dev/
- Krkn | CNCF:https://www.cncf.io/projects/krkn/

連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- KubernetesのDiscovery&LBリソース(その1)
- KubernetesのDiscovery&LBリソース(その2)
- Kubernetesの基礎
- 「Inspektor Gadget」でKubernetesクラスタをデバッグする
- Oracle Cloud Hangout Cafe Season5 #5「実験! カオスエンジニアリング」(2022年5月11日開催)
- Red HatがOpenShift向けカオスエンジニアリングツールKrakenを発表
- KubernetesのWorkloadsリソース(その1)
- Project CalicoをKubernetesで使ってみる:構築編
- KubernetesのWorkloadsリソース(その2)
- KubernetesのConfig&Storageリソース(その1)