【CNDS2025】LLM時代の複雑な処理ニーズに応えるCloud Native ML基盤の標準化とその進化

サイバーエージェントのCycloud ML Platform Teamに所属し、KubernetesのWG BatchでTechnical Leadも務める岩井佑樹氏が、CloudNative Days Summer 2025のキーノートに登壇。「Standardizing CloudNative ML Computing Platforms」と題し、ML(機械学習)/LLM(大規模言語モデル)における多様かつ高密度な要求に応える次世代ML基盤の標準化動向を詳しく解説した。KubernetesのOSSコミュニティにおける最新動向と、岩井氏が深く関わる実際のプロジェクト経験をもとに、技術仕様の進化、その背後にある哲学、そして業界横断の共創が生み出す新たな「標準」のかたちを描き出す講演となった。
ML/LLM時代に求められるCloud Native基盤の変革
講演は、MLがビジネスで価値を生むまでの一連の流れである「MLライフサイクル」の解説から始まった。このプロセスは、データ収集・加工からモデル開発、トレーニング、そして最終的な推論(inference)まで多くのステップを含んでいる。「皆さんがChatGPTなどで質問をした際に触れているのは、この『inference serving(インファレンス・サービング)』と呼ばれる部分です」と岩井氏は説明し、ユーザーが触れる機能の裏側で膨大な処理が動いていることを強調した。
このライフサイクルは、データ処理を担う上位層の「データプラットフォーム」と、計算処理を実行する下位層の「コンピューティングプラットフォーム」に大別される。本講演の焦点は後者であり、Apache Sparkによるデータ準備、Jupyterでのモデル開発、PyTorchを用いたトレーニングなど、多様なOSSが連携して動作する領域だ。
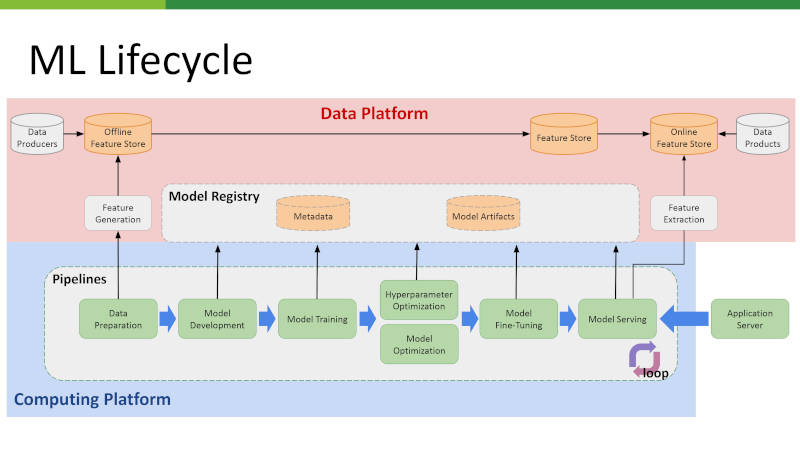
ML Lifecycle
これらの複雑なワークロードを統合管理する基盤として、KubernetesはPodという単位でリソースを抽象化し、スケーラブルな運用を可能にする中核的な役割を担う。しかし岩井氏は、従来のKubernetes単体では、ML/LLMが求める高密度な計算リソースの制御やリアルタイム性への対応には限界があると指摘。従来のWebアプリケーションとはまったく異なる要件に応えるため、Kubernetesと各種OSSをより深く統合し、リソース制御やデバイス管理まで含めて全体を最適化する「次世代のCloud Native基盤」の必要性を訴えた。
Kubernetesコミュニティによる標準化の進展とその狙い
この課題に対しKubernetesは今、単なる実行環境から、技術標準を形成する中核へと進化している。その進化は、特定のベンダーではなく、OSSコミュニティ主導で進められている点が注目される。
岩井氏は「Kubernetesの技術推進体制には三つのレベルがあり、特定の技術を扱うSIG(Special Interest Group)、そして複数のSIGを束ねて広い課題に取り組むWG(Working Group)が中心となって標準化を進めています」と解説する。
ML/LLM領域での取り組みは、2022年の「WG Batch」設立とともに本格化した。当初はトレーニングやバッチ処理、およびGPUなどのデバイス活用を広く扱っていたが、専門性の高まりを受け、2024年には「WG Device Management」が独立。岩井氏はその背景を「GPU、TPUといった高機能デバイスを使いこなすには専用の設計が必要です。Kubernetes上からもっと集中して管理しようという流れになりました」と語る。
同じく2024年には、LLMの推論処理に特化した「WG Serving」も新設された。こちらでは、トークンサイズに応じたGPUの最適選定や、キャッシュ配置を考慮したルーティングといった、従来のWebサービスとは次元の異なる要件が議論されている。
これらのWGは、OptunaやVLLMといったML系OSSと密に連携し、現実のユースケースを反映した仕様をKubernetes本体や周辺プロジェクトに還元している。「KubernetesとMLのエコシステムが一緒に、ひとつの標準を作っていく。そうした場面が本当に増えてきました」という岩井氏の言葉通り、コミュニティは今や互いの進化を促す共創関係を築いている。この実装を起点としたオープンな標準化こそが、Kubernetesの進化を加速させる原動力なのである。
Cloud Native ML基盤を支える技術仕様の全貌
コミュニティでの議論を経て、ML/LLMワークロードを効率的かつ安定的に運用するための具体的な技術仕様が整備されつつある。次に岩井氏は、現在標準化が進む中核技術を体系的に紹介した。
デバイス管理の高度化(DRA)
従来、物理単位でしか扱えなかったGPUを、仮想的に分割・共有可能にするのがDRA(Dynamic Resource Allocation)だ。これによりリソース効率を最大化し、動的な構成変更や障害回避を柔軟に行えるようになる。
グループ単位のPod制御(PodGroup)
数千のPodが一斉に動作する大規模トレーニングでは、個々のPod制御は非効率である。そこで「PodGroup」という単位を新たに導入し「すべてのPodが揃わなければ処理を開始しない」といったAll-or-Nothing型の協調動作を実現する。
高速な障害復旧(In-place Restarting)
障害発生時、Pod全体ではなく問題のあるコンテナだけをその場で再起動する「in-placeリスタート戦略」の導入も進む。これにより、復旧時間を大幅に短縮し、インフラ効率の向上を図る。
公平なリソース分配とスケジューリング
マルチテナント環境では、ワークロードごとのQuota(利用枠)を管理し、クラスター全体でリソースの公平性(Fairness)を保つ仕組みが不可欠だ。さらに推論時にはモデルやキャッシュの配置、リクエストのトークンサイズまで考慮した高度なトラフィック制御(Traffic Scheduling)が求められる。
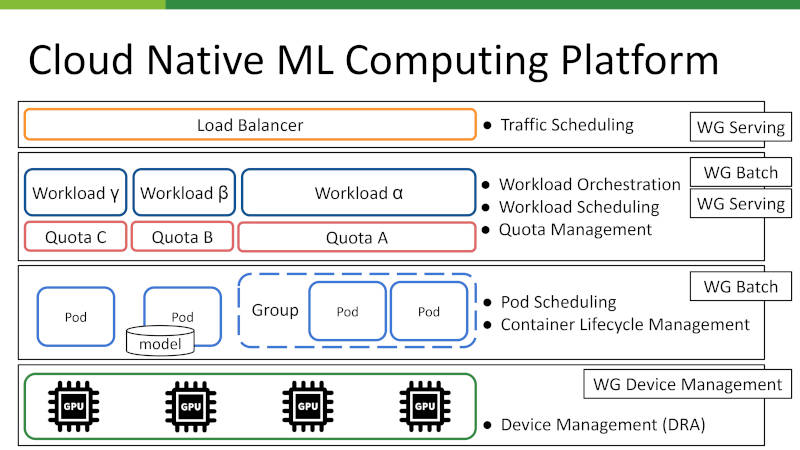
Cloud Native ML Computing Platform
これらの技術は、デバイス、Pod、ワークロード、トラフィックという複数のレイヤーで連携し、ML/LLMに最適化された高信頼な実行環境を形作る。これこそが、Kubernetesコミュニティが描く次世代の「標準仕様」の姿である。
OSSコミュニティとともに進める「標準化」の実践
こうしたCloud Native ML基盤の標準化は、単なる仕様策定ではなく、多様な関係者による「共創」のプロセスそのものに支えられている。岩井氏は、OSS開発の現場では、個人の善意だけでなくフルタイムで活動するプロの貢献者も多く、異なる企業のユースケースが衝突することも日常茶飯事だと語る。
例えばGPUリソースの扱い一つでも、リアルタイム推論を重視する事業と、大規模トレーニングを重視する事業では理想形が異なる。「もちろん喧嘩をしたいわけではなく、より良いものにしたいという思いで話し合っています」と岩井氏が言うように、こうした意見の対立こそが、特定の用途に偏らない汎用的な仕様を生み出すための健全なプロセスなのである。
Work together with ML Ecosystem
岩井氏は、迅速さが求められる内製開発と、再利用性や相互運用性を重視するOSS標準化の違いに触れ、「標準化された技術を使うのではなく、自ら技術を標準化する。そうすることで各社がその標準を土台にして新たなビジネスを展開できます」とその意義を強調した。この言葉には、単なる技術の利用者にとどまらず、標準を創り出す側になることの重要性が込められている。
Cloud Native ML基盤の進化は、岩井氏のように現場の知見をコミュニティに還元し、対話と調整を重ねる実践者たちの「共創」によって支えられている。標準とはトップダウンで与えられるものではなく、多様な視点が交差する中で創発的に立ち上がる成果物なのである。

連載バックナンバー


Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
- KubeCon Europe 2025、3日目のキーノートでGoogleとByteDanceが行ったセッションを紹介
- 【5/23開催直前!】クラウドネイティブの最前線を沖縄で体感!「CNDS2025」見どころガイド
- KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
- KubeCon North America 2024、日本からの参加者を集めて座談会を実施。お祭り騒ぎから実質的になった背景とは?
- 生成AI向け機械学習クラスター構築のレシピ 北海道石狩編
- 【CNDS2025】国産クラウドが目指すCloudNativeの未来 さくらのクラウドの進化と展望
- KubeCon+CloudNativeCon Europe 2025から初日のオープニングキーノートを紹介
- KubeCon Europe 2025、GoogleとMicrosoftがSIG発の管理用ツールを紹介
- KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介