「WSL」を使って、話題の生成AI「Ollama」をWindowsで簡単に動かしてみよう

はじめに
近年、生成AI(Generative AI)が急速に普及しています。その中でも、特に大規模言語モデル(LLM:Large Language Model)はプログラミングのアシスタントとして有用で、ITエンジニアの注目を集めています。また、AIを利用した開発支援ツールも数多く登場しています。「ChatGPT」や「GitHub Copilot」といったサービスが有名ですが、機密保持の都合上、こうしたサービスの利用が禁止されている企業もまた多いのではないでしょうか。
こうした背景から、自分のローカル環境で動作するLLMへの関心も高まっています。ローカルLLMの利点は、何よりプライベートなデータを外部に送信する必要がないことです。また、カスタマイズの自由度が高く、特定の用途に特化したモデルを選択することもできます。
現在、多くのAI系のツールは実行環境としてLinuxを前提としているため、Windows上で動かそうとすると面倒な設定が必要なケースも珍しくありませんが、WSLを使えば、こうしたツールも簡単に動かすことができるのです。そこで今回は、WSLを使ってローカルLLMの代表格とも言えるツール「Ollama」をWindows上で動かす方法を解説します*1。
*1: Ollamaに限って言えばWindows版が提供されているため「WSLがないと動かない」ということはありませんが、多くのAI系ツールがLinuxファーストの開発アプローチを取っているため、WSLが有用である点は変わらないでしょう。また、WindowsでOllamaを使うにもLinuxと同じセットアップ手順がそのまま動くというのは、環境整備面においてメリットとも言えます。WSLのNVIDIA GPU対応
大規模なモデルを扱う場合、CPUだけでは応答に数分単位で時間がかかることもあります。そのため、大前提としてLLMを現実的な速度で動作させるには、GPUによる支援が欠かせません。しかし、WSLの実体はHyper-Vの仮想マシン上で動くコンテナです。こうした環境において、はたしてWindowsのGPUを利用できるのか、不安に感じる方もいるのではないでしょうか。
R495以降のNVIDIA GPUドライバとバージョン5.10.43.3以降のWSL2カーネルは、WSL2内でのNVIDIA CUDAの利用に対応しています。そのため、よほど古いドライバとカーネルを使用していない限り、問題なく動作すると言えるでしょう。
NVIDIA GPUドライバのバージョンは、NVIDIAコントロールパネルから確認できます。「システム情報」を開くと、以下のようにGPUのモデルと「ドライバーのバージョン」が表示されます。
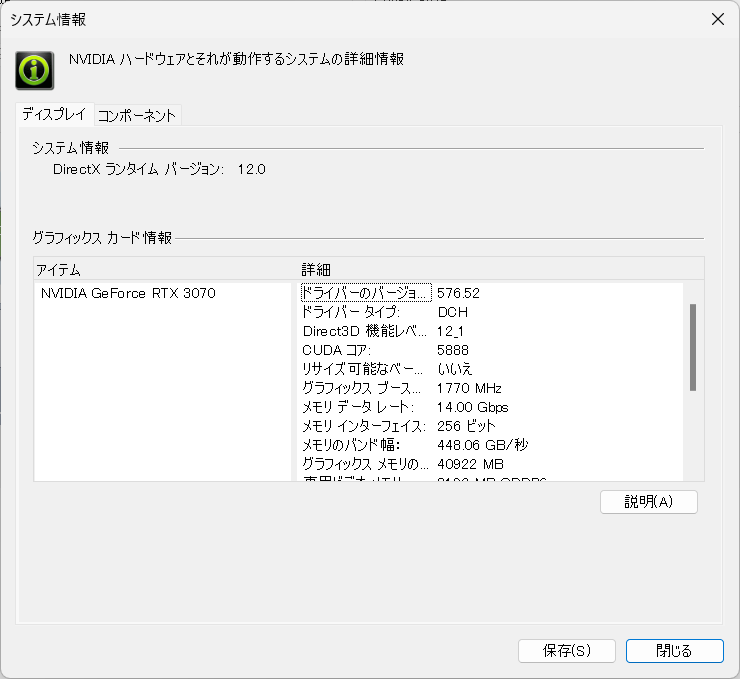
NVIDIA GPUドライババージョンの確認
カーネルのバージョンを確認するには、Ubuntuのシェルで以下のコマンドを実行してください。
$ uname -r
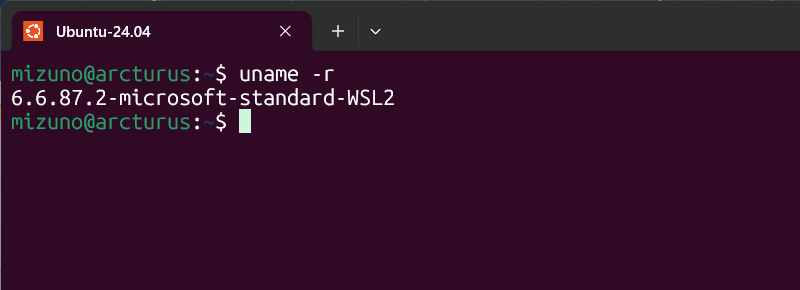
WSL2カーネルバージョンの確認
WSL内でGPUが正しく認識されているかは、Ubuntuのシェルで「nvidia-smi」コマンドを実行して確認します。
$ nvidia-smi
以下のように出力が表示されれば、WSL内でGPUが正常に認識されています。
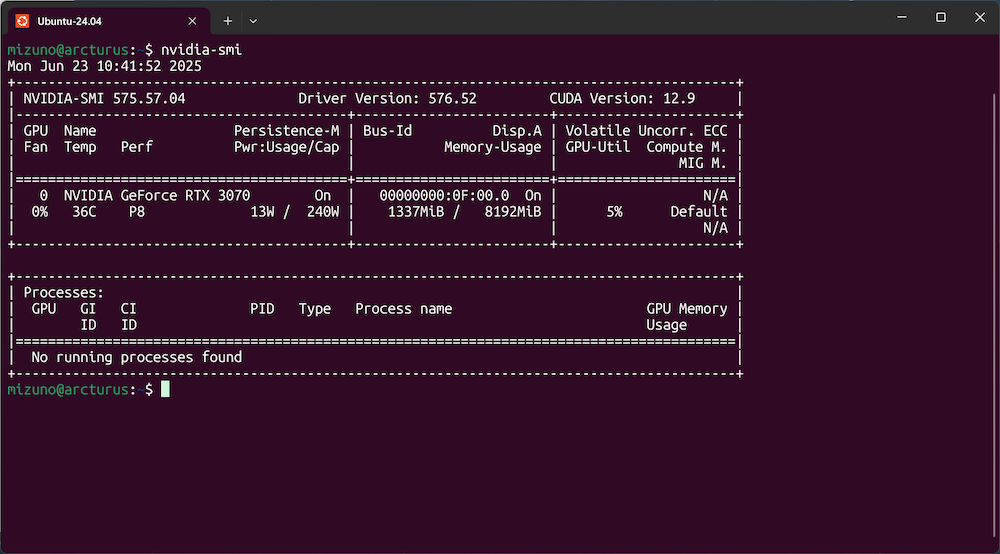
Windows上で確認したのと同じGPU(RTX 3070)や同じドライバのバージョン(576.52)をWSL内からも認識している
ここで重要な注意点として、NVIDIAのドライバはWindowsにのみインストールするようにしてください。WSL内にNVIDIAのLinuxドライバをインストールしてはいけません。
WSLのUbuntuでOllamaを動かす
Ollamaは様々なLLMを簡単に実行できるツールです。Meta社の「Llama 4」、Google社の「Gemma 3」、Microsoft社の「Phi-4」など、多くの人気モデルをサポートしています。コマンド1つで使いたいモデルをダウンロードして実行できるため、複雑な環境構築も不要で、手軽にLLMを試せます。
本連載で繰り返しお伝えしているように、WSL内のUbuntuはユーザーランド(OS内の一般ユーザーの権限で操作できる領域)レベルでは基本的にベアメタルに直接インストールしたUbuntuと変わりません。つまり、これ以降の手順は通常のUbuntuでOllamaを動かす手順と完全に同一です。WSL以外でUbuntuを使用している方も参考にしてください。
Ollamaのインストール
Ollamaのインストールは非常に簡単です。公式が提供しているシェルスクリプトをダウンロードして、以下のように実行してください*2。このスクリプトは、Ollamaの最新バージョンを自動的にダウンロードしてインストールします*3。
$ curl -fsSL https://ollama.com/install.sh | sh >>> Installing ollama to /usr/local [sudo] password for mizuno: >>> Downloading Linux amd64 bundle ######################################################################## 100.0% >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> Nvidia GPU detected. >>> The Ollama API is now available at 127.0.0.1:11434. >>> Install complete. Run "ollama" from the command line.
上記のように「Install complete. Run "ollama" from the command line.」と表示されればインストールは完了です。Ollamaのサービスが起動して「ollama」コマンドが使用可能になります。
念のため、サービスが正常に起動しているかを確認しておきましょう。「ss」コマンドを実行すると、11434番ポートをollamaプロセスが待ち受けていることが分かります。
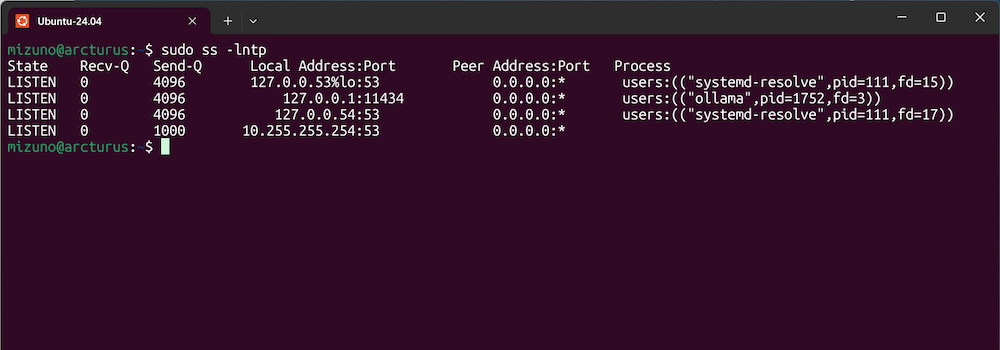
Ollamaサーバーは11434番ポートで待ち受ける
このポートにcurlコマンドでアクセスしてみましょう。サービスが正常に稼動していれば「Ollama is running」という応答が返ってきます。
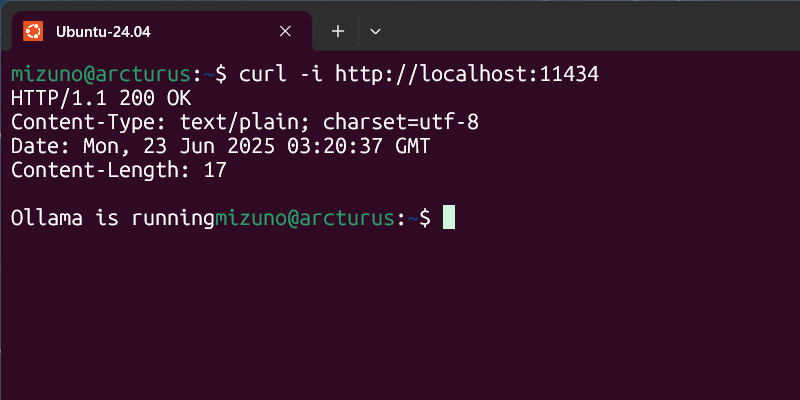
HTTPでOllamaにアクセスしてみる
*2: 今回は説明を簡略化するため公式のインストール手順をそのまま紹介していますが、インターネットからダウンロードしたスクリプトを直接実行するのはセキュリティ的なリスクがあるため避けてください。悪意のあるコマンドを知らずに実行してしまうことを避けるためにも、スクリプトは一度手元にダウンロードして、中身を確認することをお勧めします。
*3: このスクリプトは、Ollamaのインストールの後に環境に応じたNVIDIAのドライバもインストールしようとしますが、前述の通りWSL2環境ではLinux向けのドライバをインストールする必要はありません(してはいけません)。そのため、WSL2環境で実行されていることを検出した場合はドライバのインストールプロセスをスキップするようになっています。
モデルのダウンロードと実行
Ollamaを動かすには、まず使用したいモデルをダウンロードします。モデルごとにパラメータ数などが異なり、それによって性能や実行速度も変化します。基本的にパラメータ数の多いモデルの方が高機能ですが、パラメータ数は計算量に直結するため、こうしたモデルは処理時間が長くなる傾向にあります。今回は一般的なPCでも現実的な時間で動かせて、また日本語で利用できる軽量モデルということで「Llama 3.1」の8Bパラメータ版を使用しました。
以下のコマンドでダウンロードします。
$ ollama pull llama3.1:8b
ダウンロードが完了したら、以下のコマンドを実行してください。
$ ollama run llama3.1:8b
Ollamaのプロンプトが表示され、モデルとの対話が可能になります。ここに質問を入力してみましょう。
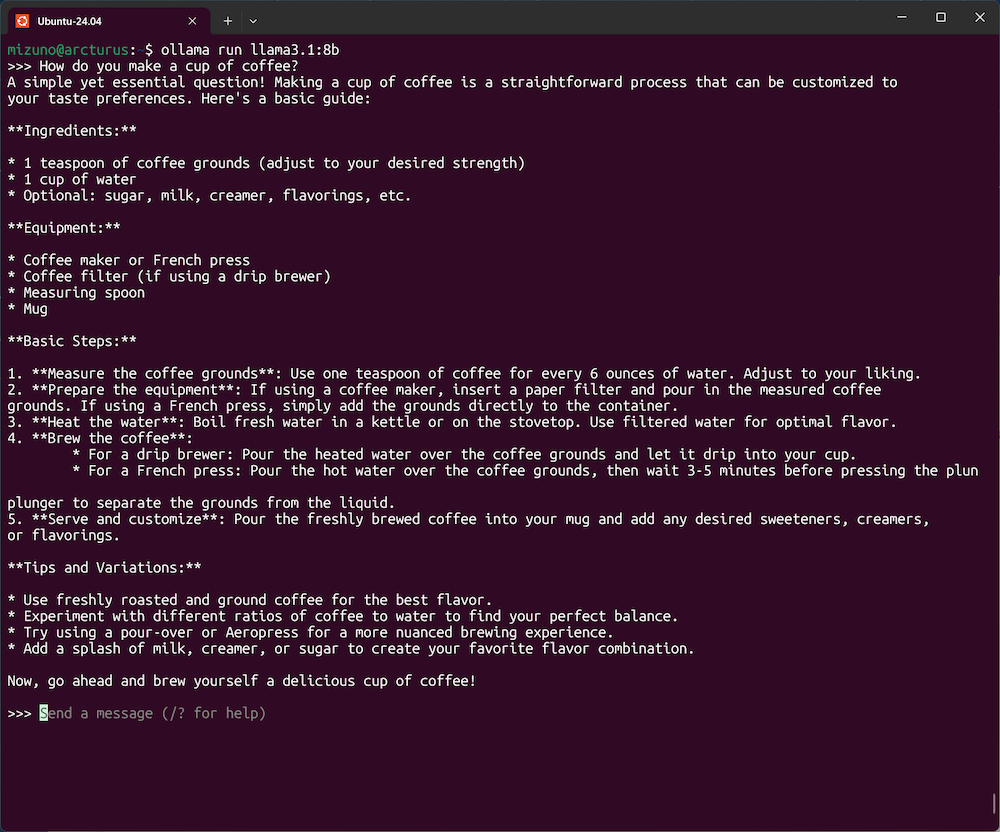
プロンプトに質問を入力すると返答が返ってくる

日本語での対話も可能
このように、自然な日本語や英語で質問をすると、回答を返してくれます。
ただし、今回使用したLlama 3.1はパラメータ数が8B個しかなく、性能的にはそれほど期待しない方がよいでしょう。特に複雑な計算や推論は苦手としているため、情報を提供するタイプの質問や簡単な推論に留めておくのが吉です。より新しく、パラメータ数の多いモデルを使えばこの問題は改善できるのですが、それ相応に動かすPCのスペックも求められるようになってしまいます。
GPUの有無による性能の比較
前述の通り、現在のWSLは特別なインストールや設定作業を行わなくてもGPUを利用できますが、実際のところGPUの恩恵はどの程度あるのでしょうか。意図的にGPUを無効化して、性能を比較してみましょう。Ollamaではプロンプトに「/set parameter」と入力することでパラメータを指定できます。ここで「num_gpu」を「0」に設定するとGPUを無効化できます。
また、ollamaコマンドは引数に文字列を指定することで対話的プロンプトに入らず、回答を求めることができます。
$ ollama run llama3.1:8b 'フィボナッチ数を、N番目まで計算して表示するシェルスクリプトを書いて'
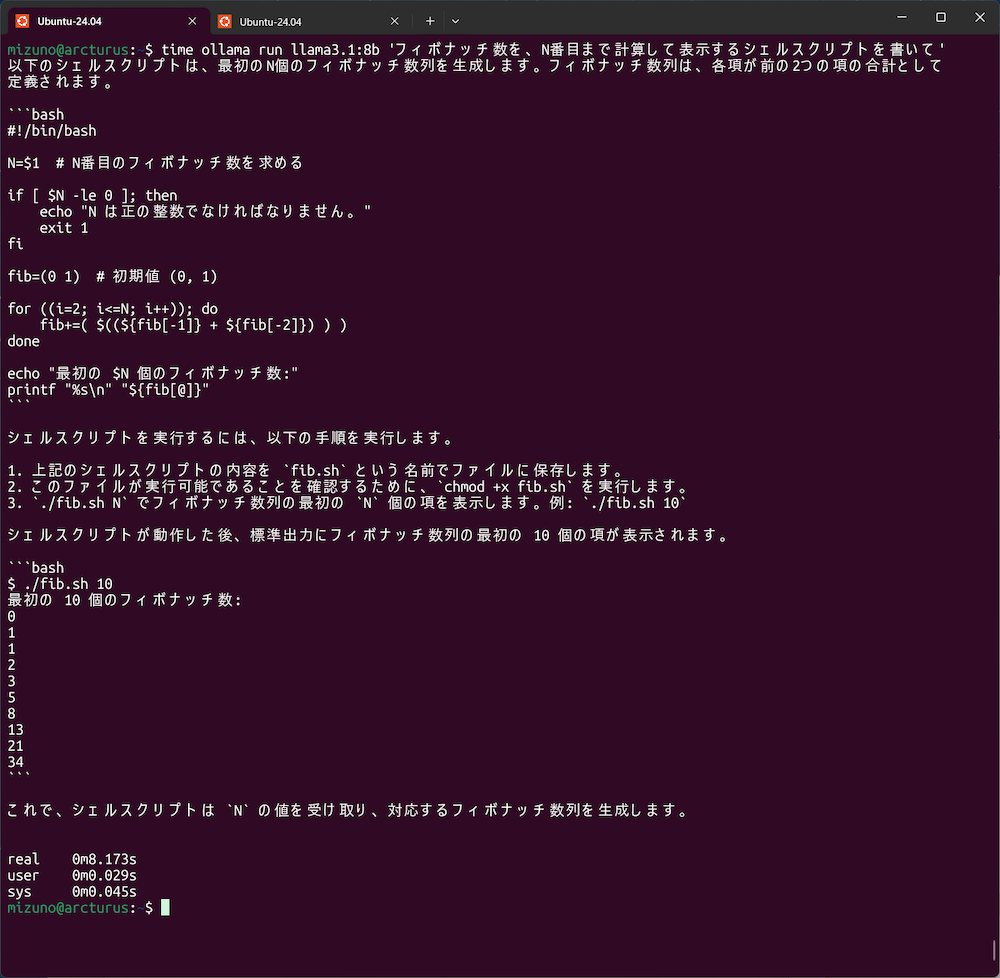
timeコマンドを使って回答にかかる時間を測定した
これをtimeコマンドと組み合わせて、GPUありとなし(CPU実行)の実行時間を測定しました。また、回答の内容でかかる時間は前後するため、10回ずつ試行して平均を測定した結果が以下の表になります。
| GPU有効 | GPU無効 | |
|---|---|---|
| 1回目 | 5.130 | 42.2 |
| 2回目 | 5.061 | 43.622 |
| 3回目 | 6.732 | 92.932 |
| 4回目 | 3.369 | 54.929 |
| 5回目 | 7.480 | 44.643 |
| 6回目 | 5.030 | 60.485 |
| 7回目 | 7.413 | 62.504 |
| 8回目 | 6.130 | 43.526 |
| 9回目 | 5.068 | 56.137 |
| 10回目 | 7.318 | 44.631 |
| 平均 | 5.8731 | 54.5609 |
見ての通り、GPUを使用すればおおむね5秒前後で回答が得られるのに対し、CPUで実行した場合は10倍以上の時間がかかっていることが分かります。つまり、今回のケースでは少し古めのPC向けGPU(RTX3070)程度でも、CPU(Ryzen 9 5900X)と比較して10倍の性能向上が得られたということです。この性能差は、長い文章の生成や複雑な質問、また使用するGPUの性能によって、さらに顕著となるでしょう。
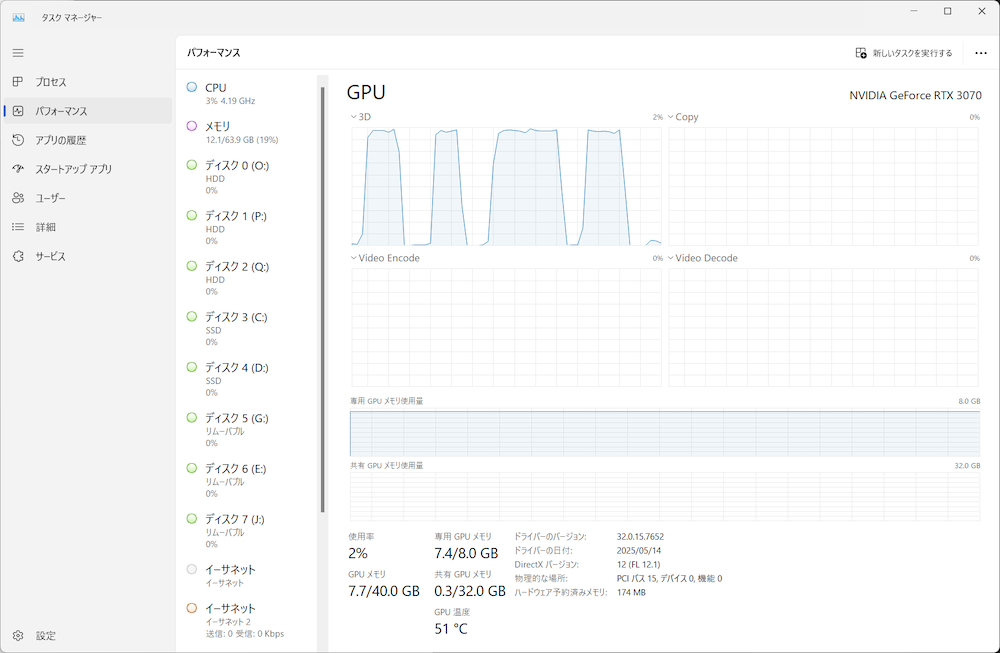
GPUを使う設定でOllamaを動かした状態。回答を生成している際にGPUが使用されている
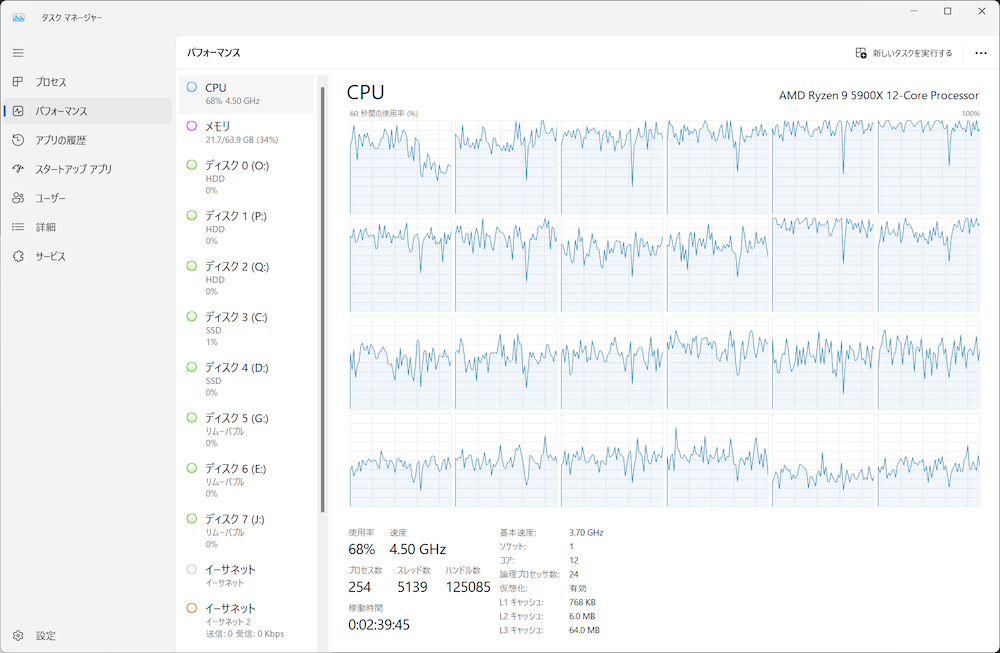
対してGPUを無効にしてOllamaを動かした状態。CPUの全コアがほぼほぼ使用されている
Windows上のVS CodeからOllamaに接続する
普段使いのツールからAIを透過的に利用できると便利です。「Visual Studio Code」などの開発環境にはAIによるアシスト機能を追加する拡張機能が用意されています。例として、VS CodeからWSL内で起動したOllamaを利用してみましょう。
VS Code拡張機能のインストール
まず、VS CodeにMicrosoft製の拡張機能である「AI Toolkit for Visual Studio Code」をインストールします。
AI Toolkit for Visual Studio Codeのインストール
左のアクティビティバーにAI Toolkitが追加されるのでクリックします。続いて「Open Model Catalog」をクリックしてください。AIのモデルを選択する画面が表示されたら「Add model」をクリックします。
画面中央右にある「Add model」をクリックする
クイックピックでオプションを選択してください。まず「Add Ollama Model」を選択します。

Add Ollama Modelをクリックする
次に「Select models from Ollama library」を選択します。

Select models from Ollama libraryをクリックする
最後に既にダウンロード済みのモデル(ここではllama3.1:8b)が表示されるので、選択して「OK」をクリックします。

llama3.1:8bを選択してOKをクリックする
これでVS CodeからOllamaを使用するための準備は完了です。
VS Code上からOllamaを利用する
アクティビティバーからAI Toolkitを開いて「TOOLS」→「Playground」をクリックすると、プレイグラウンド画面が開きます。ここで先ほどコマンドラインから行ったのと同様にOllamaと直接対話できます。「Type a prompt」と書かれたテキストボックスに質問を入力して、応答が返ってくるかを確認してください。
先ほどLlama 3.1が生成したフィボナッチ数列を生成するシェルスクリプトをテキストボックスにペーストして、リファクタリングさせてみた例が以下です。
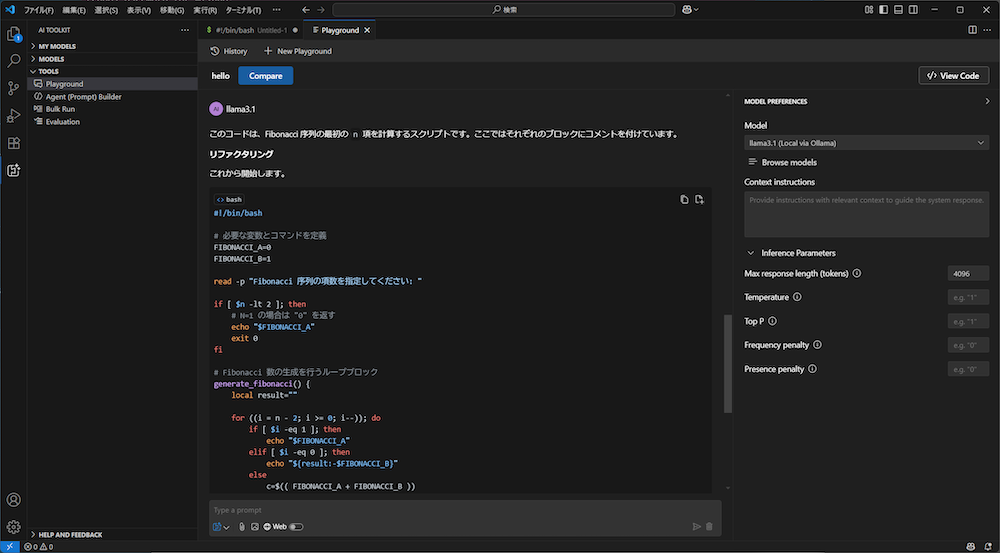
コマンドラインを使わずとも、いつものVS CodeからOllamaを直接利用できる
おわりに
今回は、WSLを活用してWindows環境でローカルLLMを動作させる方法について解説しました。現在のWSLはGPUに対応しているため、複雑な設定なしで手軽にAI環境を構築できることに驚いた方もいるのではないでしょうか。GPUを活用することで、一般的なPCでも実用的な応答速度でAIアシスタントを利用できます。
また、VS Codeなどと連携すれば、普段の開発ワークフローにAI機能を組み込むことも簡単です。特に機密性の高いプロジェクトでクラウドベースのAIサービスが利用できない場合は、検討する価値はあるでしょう。
WSLは単なるLinux互換環境ではなく、Windows開発者にとって強力なツールです。Ollama以外にも多くのAI・機械学習ツールがWSL上で動作します。WSLを活用したAI開発環境の構築に、ぜひチャレンジしてみてください。

連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- Windowsでもコンテナを使いたい! WSLで「Docker」に入門しよう
- 「WSLg」を使ってWindows上でLinuxのGUIアプリを動かしてみよう
- 「WSL2」をインストールしよう
- 「Windows Terminal」を使いこなす
- 「mmdebstrap」でUbuntuをカスタマイズして、オリジナルのWSLディストリビューションを作ろう
- 「Visual Studio Code」と「WSL」+「Docker」をもっと便利に使いこなそう
- WSL2登場でWindowsは有力なWeb開発環境に
- WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
- Windows 11でLinuxを使う:Windows Subsystem for Linux 2の設定
- Windows Subsystem for Linux 2 でDocker を使用する(その2)