KubeCon China 2025、DaoCloudが解説するLLM開発高速化のセッションを紹介

KubeCon+CloudNativeCon China 2025から、DaoCloudのエンジニアが解説する大規模言語モデル(LLM)開発に伴う課題を解決し高速化する新しいオープンソース、Datasetsに関するセッションを紹介する。タイトルは「Taming Dependency Chaos for LLM in K8s」でプレゼンテーションを行ったのは、DaoCloudのエンジニアリングチームのVPであるPeter Pan氏、シニアソフトウェアエンジニアであるKebe Liu氏、同じくFanshi Zhang氏の3名だ。

プレゼンテーションを行った3名。それぞれのGitHubアカウントも表示されている
セッションの動画は以下から参照できる。3名とも英語によるプレゼンテーションとなった。
●動画:Taming Dependency Chaos for LLM in K8s
最初にチームのリーダーであるPan氏が、LLM開発における課題について解説。開発に利用するPythonに代表される依存関係、モデルやデータセットの管理、データに関するガバナンスの3つの観点から、それぞれ問題点を列挙した。特に「私のマシンでは動いていた(けど本番環境ではエラーとなる)」問題については機械学習のデベロッパーにおいて頻繁に発生していると説明した。

「私のPCでは動いていた問題」を説明するPan氏(左)、Liu氏(中)、Zhang氏(右)
そして機械学習において、データセットを作成する手法とそのデータセットを使って推論を行うアプリケーションを開発する手法において、大きなギャップがあることを紹介。

LLM開発のパターンとDatasetによる開発パターンの違いを紹介
ここではこの後に解説されるDatasetというKubernetesのカスタムリソースを用いたツールに関して紹介しているが、この後にプレゼンテーションを行ったZhang氏は問題をより掘り下げて紹介しているため、やや唐突に回答が提示されてしまった感は否めない。

バトンタッチしたZhang氏はPythonの依存関係に関する問題点を解説
実際にはPython以外にもNVIDIAのGPUのためのSDK、CUDAのバージョンやパッケージの相違など、多くの問題点が依存関係に起因していることを紹介した。

機械学習には隠れた問題点が多く存在することを紹介
CUDAについても利用するパッケージやライブラリーがどのバージョンを要求するのかによって複雑さが増し、最終的には互換性や必要なモジュールがインストールされていないなどの問題が発生することを指摘した。

利用するCUDAのバージョンが異なることで多くの問題が発生する
同様に、GCCのバージョンの更新によってメモリーの持ち方が変わってしまったというより具体的な違いを指摘して、単にPythonだけに留まらない多くの隠れた問題点が存在することを説明した。

これまでの開発フローからReusableな環境に変更することで多くの問題点と処理時間を削減できる
このスライドではここまで挙げてきた依存関係の問題点に限らず、処理の実行のために必要な準備作業や時間が大きく削減できることを解説した。このスライドでは、従来4~6時間かかっていた作業が30秒で終わることを強調している。この違いは、CUDAやシステムライブラリーのインストレーションなどを無駄な工程として省けたことによって実現している。

pip、Docker、Nixなどを例に挙げてPro/Conを比較
これらの無駄を省くためにさまざまなツールを比較検討したとして、Pythonのパッケージマネージャーであるpipや、Docker、Nixなどを紹介。どれも必要な要件をクリアしていなかったと解説した。特にKubernetesネイティブであること、ストレージの効率化と言う部分が挙げられているのはクラウドネイティブなインフラストラクチャーを指向しているDaoCloudには必須の要件だろう。

Dataset CRDを紹介
ここからはDatasetの紹介に移って、データセットやモデルを同時に利用できること、自社で用意したModel Hubを使えること、データセットを個々にダウンロードする必要がないことなどを挙げて紹介している。

DockerとDataset CRDの比較
特にDockerとの比較については1枚のスライドを用意して解説。Dockerの欠点として新しいパッケージを入れるために毎回ビルドする必要があることなどを挙げている。それに対してDatasetの利点については、パッケージの追加は瞬時に終わること、KubernetesのストレージであるPV/PVCを使うこと、複数の環境をスイッチして利用できることなどを挙げた。

依存関係の問題に関する従来の手法とDatasetによるソリューションの比較
Pythonの依存関係問題の解決には、pipに加えてCONDAと呼ばれるパッケージマネージャーを意識する必要があるだろう。pipはPythonのコードだけのパッケージマネージャーであるのに対し、CONDAは依存するPython以外のモジュールもインストールできる。しかし依然としてインストールなどの準備工程の所要時間は短縮できず、環境を再利用/共有できない、個々に環境を維持する必要があることは変わっていない。
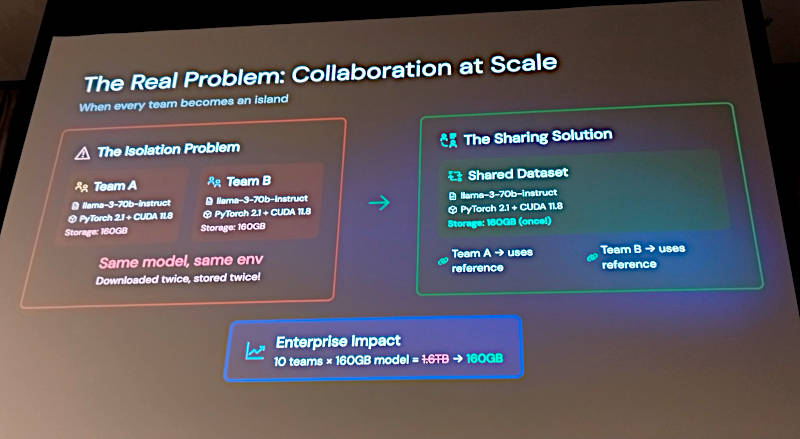
個々に環境を準備する必要がある方法と環境を共有することでストレージを削減可能に
ここではDatasetによるデータセットを再利用する手法を従来の手法と比較して解説している。個々にデータセットを用意することが毎回発生してしまうという点を、PVCを共有することでクリアしていることが強調されている。
Pythonのパッケージマネージャーに関する問題点の解決には、Pixiと呼ばれるRustで書かれた新しいパッケージマネージャーの存在が大きいと思われる。次のスライドではCONDAとPixiの比較を行っている。

CONDAとPixiの比較
ここでもインストールなどのセットアップにかかる時間が大幅に削減されていることを説明した。Pixiについては以下の公式ページを参考にして欲しい。PixiはRustのパッケージマネージャーであるCargoを参考にして、CONDAの置き換えを目的に開発されているという。LLMにおけるPythonの問題点が主題のこのセッションにおいては必要なピースということだろう。
●参考:https://github.com/prefix-dev/pixi
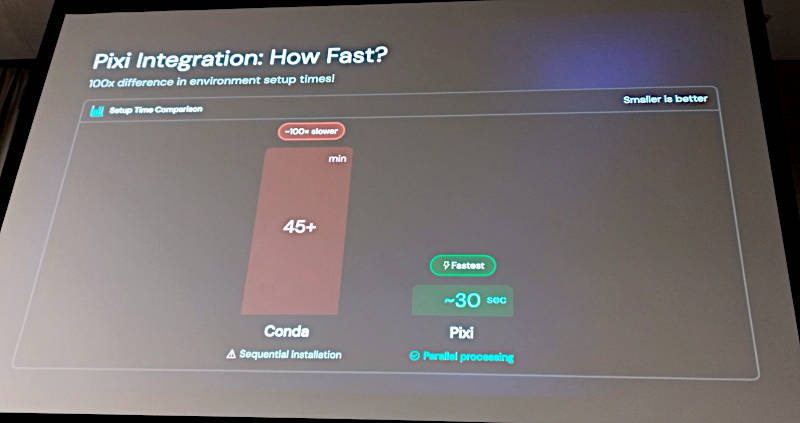
PixiとCONDAの性能比較
CONDAとPixiのセットアップ時間の比較を見せて解説。ここではCONDAの45分に対して、Pixiは30秒という処理時間が紹介されているが、主な違いはシーケンシャルに処理を行うCONDAに対して、Pixiは並列処理を行うことである。これこそがPixiが高速な要因だ。

Datasetによる従来のワークフローとの違いをまとめて紹介
ここでセットアップ時間の短縮、データセットの再利用によるストレージの削減などを挙げて、Datasetによる効果を紹介した。これ以外にもネームスペースを使ったデータセットの再利用、モデルをカタログ的に利用可能にしたことなども紹介されている。

モデルのカタログ化にとって複数のモデルを使い分けることが可能に
ただしモデルのリポジトリについてはHugging FaceとAlibabaが用意しているModelScopeのサポートであると紹介されていることから、中国のLLMエンジニアに限定した機能であることは注意点だろう。
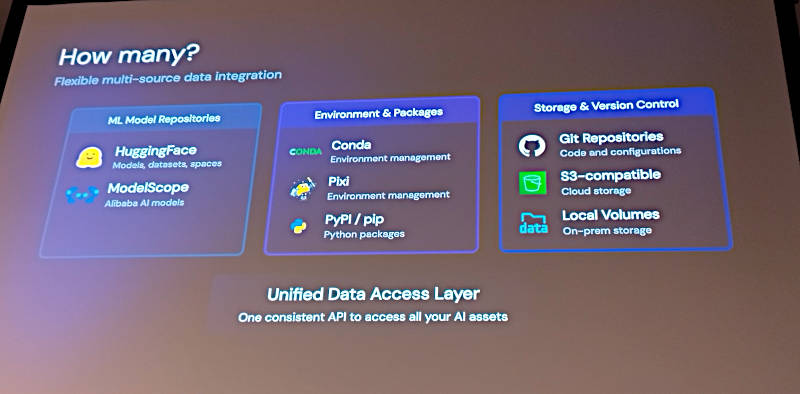
対象となるモデルリポジトリはHugging FaceとModelScope(Alibaba)のサポートのみ
より詳細には以下の公式GitHubページを参照されたい。
●公式ページ:https://github.com/BaizeAI/dataset
LLM開発の問題点をKubernetesの手法に沿って解決するDatasetだが、一般名詞的で地味な名称が助けになってないことはマイナスポイントだろう。さらにDatasetだけではなく、CONDAの置き換えを目指すPixiがどれだけ支持を増やしていけるのかという点にも注目していきたい。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています





全文検索エンジンによるおすすめ記事
- KubeCon China 2024、Kubernetes上でMLジョブのフォルトリカバリーを実装したKcoverのセッションを紹介
- KubeCon Japan 2025、HuaweiとDaoCloudによる2日目のキーノートを紹介
- KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
- KubeCon China 2024、GPUノードのテストツールKWOKを解説するセッションを紹介
- 生成AIはソフトウェアテストをどのように変えるのか 〜mablに聞く、テスト自動化におけるLLM活用の展望と課題
- 「Dockerfile」を書いてコンテナを構築してみよう
- KubeCon Japan 2025、LLMの起動を高速化するBentoMLのセッションを紹介
- 関数型Linuxディストリビューション「NixOS 24.11」リリース
- WasmCon 2023からLLMをWASMで実装するセッションを紹介
- AI_dev Europe 2024から生成型AIのオープンさを概観するセッションを紹介