KubeCon Japan 2025、LLMの起動を高速化するBentoMLのセッションを紹介

KubeCon+CloudNativeCon Japan 2025から、サンフランシスコのスタートアップBentoMLによる、大規模言語モデル(LLM)や機械学習ジョブの起動を高速化する新しいPythonライブラリーを解説したセッションを紹介する。

LLMの起動を高速化するBentoMLを解説するセッション
KubeConはセッションの概要を記述したCall for Presentation(CFP)の採用率が10%台という高い競争率であることから、たとえ名前が知られた大企業であってもそこを突破するのは非常に難しい。一方でそのセッションの訴求ポイントが参加者にとって有用であるとCNCFが判断すれば、たとえ無名のスタートアップであっても突破できる可能性は高い。今回はそんなスタートアップが行ったLLMアプリケーションを高速に起動するための仕組み、BentoMLを解説したセッションを紹介する。プレゼンテーションを行ったのはBentoMLのシニアエンジニア、Fog Dong氏だ。タイトルは「Zero-Extraction Cold Starts: How FUSE-Streaming Slashed ComfyUI Cold Starts bt 10x」、「FUSEのストリーミングを使ってLLMのコールドスタートを10倍高速化する」という意味だ。ちなみにDong氏は2023年に上海で開催されたKubeCon ChinaのCo-Chairパーソンであり、かつてはAlibabaやByteDanceでクラウドネイティブなシステムの構築に携わり、現在はBentoMLでAIアプリケーションの開発に関わっているという。

プレゼンテーションを行うFog Dong氏
プレゼンテーションはLLMアプリケーションを必要に応じてコールドスタートさせることがコストやコンピューティングリソースの無駄を減らすには最適であるとした一方で、コールドスタートする課題があることを紹介するところから始まった。

常にアプリケーションを実行するより必要に応じてコールドスタートする利点を紹介
しかし実際にはコールドスタートさせるには大きな課題が存在するとして紹介したのはComfyUIのワークフローだ。
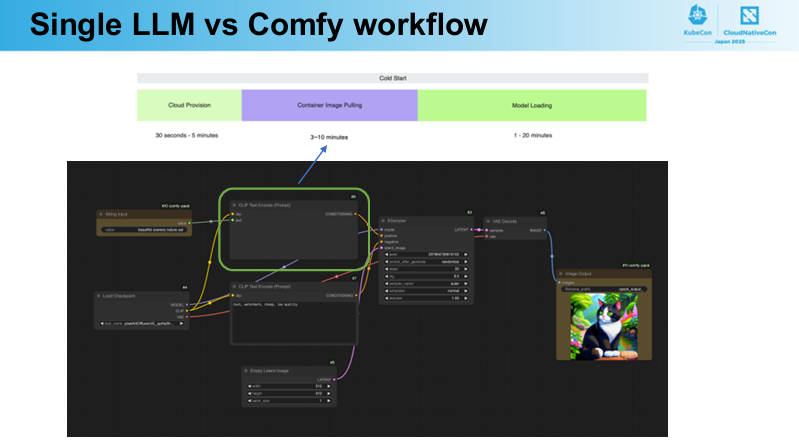
ComfyUIを使ってLLMアプリがどのように起動するのかを解説
このフロー図の中で緑色の枠で囲まれているのが、LLMのイメージをリポジトリからPullしてくる処理を指している。大きなモデルになればなるほど、メモリーへロードする以前のデータ転送に時間がかかっていることを示している。
ちなみにこのComfyUIは、GitHubで公開されているグラフィカルなUIを使ってさまざまなモデルの実行をワークフロー化するツールである。
●ComfyUI:https://www.comfy.org/
実際にシンプルなWebアプリとLLMアプリを比較した場合でどのくらいアプリケーションのサイズが異なるのか?を示したのが次のスライドだ。

PythonのアプリとLLMアプリのサイズの比較。モデルデータが15GBというサイズ
巨大なモデルデータは生成AIには必須であるためにこのプロセスを省くことはできないが、それを高速化するためにはどうすれば良いのかを解説していく内容となっている。次のスライドではLLMのモデルデータを含むコンテナをダウンロードする時間とそれをレイヤーごとに解凍する時間が最も長いことを示している。

モデルのダウンロードと解凍に時間がかかっていることがわかる
ではどうしてそこに時間がかかるのか? を解説したのが次のスライドだ。

コンテナレジストリからのダウンロードと解凍に時間がかかる要因を解説
ダウンロード処理がシングルスレッドであること、解凍がシーケンシャルに実行されること、コピーオンライト(Copy-on-Write)によってデータの書き込みが二度手間になっていること、すべてのレイヤーがダウンロードされアンパックされる必要があることを解説。これはNTTの徳永航平氏と須田瑛大氏が開発しているコンテナイメージのLazy Pulling(プロジェクト名はStargz Snapshotter)が解決した課題と同じだ。
●参考:https://cloudnativedays.jp/cndt2021/talks/1250
●参考:https://github.com/containerd/stargz-snapshotter
そしてコンテナ用のファイルシステムに使われるドライバーがこの用途には適していないことも合わせて紹介した。

巨大なモデルデータを扱うには向いていないコンテナ用のストレージドライバー
またLLMのモデルそのものについても同様の課題があることを解説した。

LLMについてもモデルハブからのダウンロードやシーケンシャル処理などに課題がある
またどこからイメージやデータをダウンロードするのか? についてはGoogleのGARやAWSのECRを使った場合、CNCFのプロジェクトでもあるHarborを社内ネットワークに実装した場合、そしてS3などのクラウドに存在するオブジェクトストレージを使った場合で処理時間に大きな差が出てくると解説した。

GAR/ECR、Harbor、GCS/S3でダウンロードの速度と処理時間を比較
ここからモデルデータをレジストリ経由ではなくオブジェクトストレージに置いたうえで、FUSEを使って高速化する仕組みを解説した。
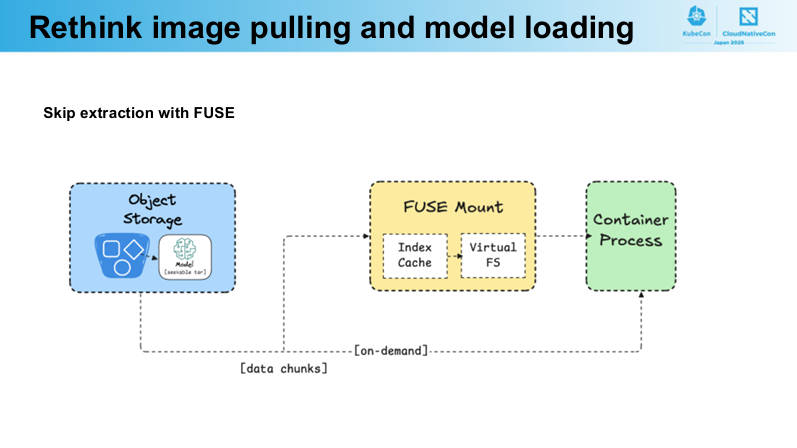
FUSEを使ってモデルデータのダウンロードを高速化
FUSEについては公式ページを参照して欲しい。
●参考:https://github.com/libfuse/libfuse
全体像を示したシステム図を用いた解説によれば、結果として実に25倍も高速化されたという。
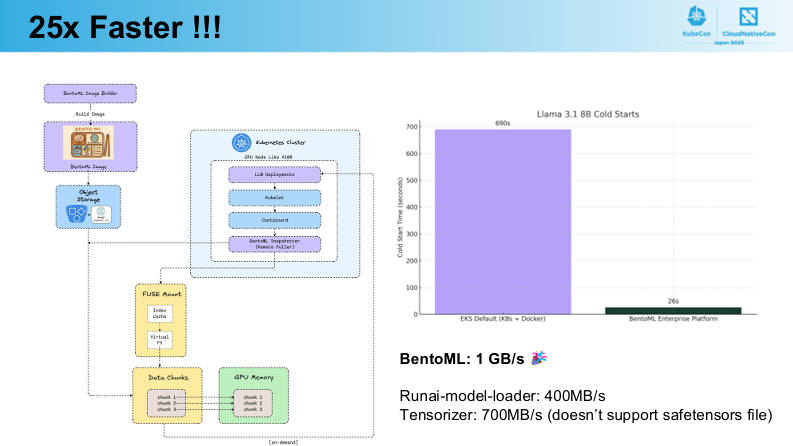
BentoMLのツールを使うことでコールドスタート時間は25倍も高速化された
注意すべきは、ここでの比較対象となっているのはEKSのデフォルト設定とBentoML Enterpriseである点だ。BentoMLの公式ページを見ると、オープンソースとして公開されているBentoMLとは別にエンタープライズ版が存在しており、ここではBentoMLが用意するGPUクラスターのレベル別に価格が設定されている。
●参考:https://www.bentoml.com/pricing
この価格表ではデータの送信量については課金対象ではないようだが、SLAやサポートエンジニアが用意されるエンタープライズ版については要相談ということになっている。

可愛らしい弁当のイラストがBentoMLのキャラクターらしい
このセッションの最後のQ&Aで「どうやってお金を儲けるんですか?」と質問しているのは筆者だが、プレゼンテーションではその部分について触れずに核心である高速化についてのみ触れていたのが印象に残った。オープンソースのカンファレンスであるKubeConにはそれが相応しいと判断した結果だろう。
LLMのコールドスタートが遅いことを課題として挙げて、その解決のために起業したと思えるBentoMLだが、実際にはSaaSとしてエンタープライズ版を用意するなどAlibaba、ByteDanceの経験が活かされているようだ。ニッチな問題を解決するために開発したソフトウェアをオープンソースとして公開し、コミュニティの力を借りるのは常套手段だが、それだけでは持続は難しい。最初に挙げた課題解決とアイデアを形にすることと同時に、どうやって売上を立てて開発を担うエンジニアが生きていくのか? という課題の一般的な解決策、それは「オープンソースをベースにしたサービスにサポートを付けてクラウドで提供して課金する」であろうが、それについてはプレゼンテーションの中では一切語られなかった。それでも、2つの面で意味のある内容だったと思われる。
動画は以下から参照して欲しい。
●動画:Zero-Extraction Cold Starts: How FUSE-Streaming Slashed ComfyUI Cold Starts by 10x
スライドは以下から。
スライド:Zero-Extraction Cold Starts
●BentoMLの公式サイト:https://www.bentoml.com/


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています




全文検索エンジンによるおすすめ記事
- KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
- KubeCon Europe 2025、3日目のキーノートでGoogleとByteDanceが行ったセッションを紹介
- KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
- KubeCon China 2024から、ローカルでLLMを実行するSecond Stateのセッションを紹介
- KubeCon China 2025、ByteDanceが開発するAIBrixのセッションを紹介
- KubeCon Europe 2025、エッジでAIを実行するKubeEdge Sednaのセッションを紹介
- KubeCon Europe 2024からWASMとeBPFを使ってストリーム処理を解説するセッションを紹介
- KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
- WasmCon 2023からLLMをWASMで実装するセッションを紹介
- Cloud Native Wasm Dayから大規模言語モデルをWasmで実行するデモを解説するセッションを紹介