KubeCon China 2025、Bloombergによるマルチクラスター抽象化のセッションを紹介

●動画:How Bloomberg Creates a Resilient Data Analytics Platform Using Karmada

セッションのアジェンダ。マルチクラスターKubernetesをKarmadaでコントロール
ここでBloombergのビッグデータ処理の概要を紹介。金融関係のデータを大量に処理する必要があること、リアルタイム分析に加えてバッチジョブによるデータ変換などさまざまな用途があること、そして障害時には分析や変換ジョブのリカバリーを確実に行う必要があることなどを要件として挙げた。

Bloombergのビッグデータ処理の要件を整理
このシステムの中核になっているのがApache FlinkとApache Spark、そしてTrinoだ。

データ分析の中核になっているのは3つのオープンソースソフトウェア
この3つのソフトウェアの使い分けは次のスライドがわかりやすいだろう。ここではリアルタイム分析をApache Flink、バッチジョブをApache Spark、データ検索はTrino、中間に存在するデータカタログにはApache HiveとApache Icebergが用意されているのがわかる。
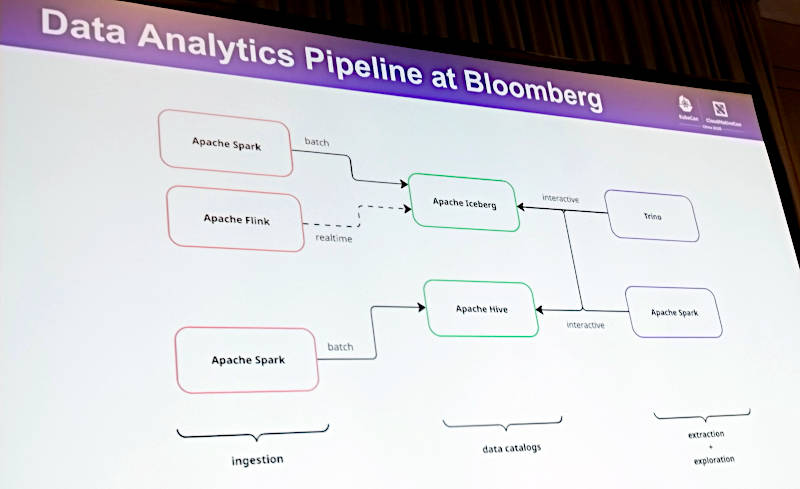
データ分析のアーキテクチャー図。データカタログにはHiveとIcebergが使われている
そしてこれらの分析のためのソフトウェアをKubernetesでオーケーストレーションするという発想だ。
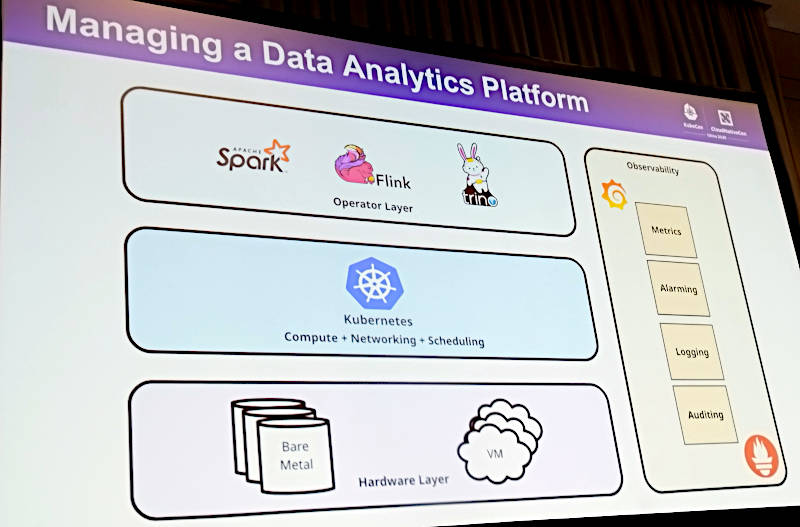
プラットフォームにはKubernetes、オブザーバビリティはGrafanaのスタックとPrometheusを利用
ここでこのシステムを構築するに当たっての解決しなければいけない課題を紹介。具体的には、単一のクラスターではなく複数のクラスターを使う必要があること、Kubernetesにおいては必須となる短期間で行われるシステムのアップデートに追従していく必要があること、障害時のリカバリーを自動化すること、そしてスナップショットなどを含めてステートフルなアプリケーションとデータに対応する必要があることなどを挙げた。ここでは特にマルチテナンシーについては触れられてはいないのが興味深い。過去のKubeCon Chinaでのセッションなどから予想すれば、中国企業のユースケースであればマルチクラスターとマルチテナンシーがセットになっていることを考えると、Bloombergほどの企業であってもマルチテナンシーが要件として挙げられていないのはやはりベースとなっている企業の組織の在り方の違いということだろうか。

データ分析システムにおける課題を紹介。マルチテナンシーが入っていないのが興味深い
そしてBloombergで分析を行うユーザーからのリクエストを抽象化して、クラスターを意識せずにアプリケーションを実装できることが求められている姿であると説明。
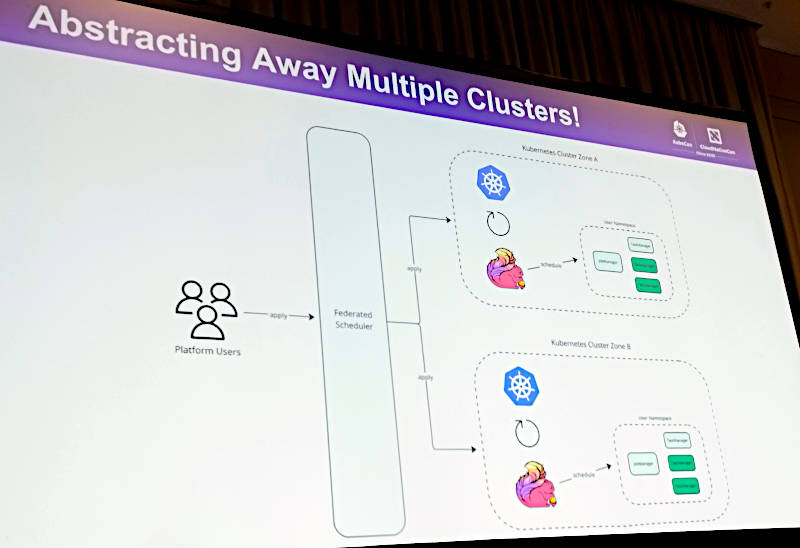
ユーザーからのリクエストをKarmadaのFederated Schedulerが受けて、複数のクラスターにスケジューリング
データ分析を行うBloombergのデータアナリストからのリクエストはなるべく抽象化して、クラスターを意識させないことが目指す理想形であると解説。Kubernetesの複数のクラスターの前にハブとしてKarmadaのFederated Schedulerが置かれていることで、ユーザーは物理的なクラスターを意識せずにデータ分析のアプリケーションを配備できるというわけだ。

2つのステークホルダーのニーズを満たすのが目的
ここでデータ分析を行うユーザーとプラットフォームの維持に責任を持つ管理者にそれぞれの目的があることを解説した。データ分析を行うユーザーにとっては容易にジョブの実行と管理ができること、安定したプラットフォームであることなどが主な目的である。他方、「プラットフォームのオーナー」と書かれている運用管理責任者の目的としてはクラスターの運用管理、メンテナンス、ディザスターリカバリーなどに加えてハードウェア利用効率の向上などが挙げられている。

マルチクラスターの運用に選択されたのがKarmada
この目的を満たすために選択されたのが、Karmadaだ。ここでは複数のKubernetesクラスターをKarmadaのコントロールプレーンから制御することで、パブリッククラウド上のクラスター、オンプレミスのクラスター、さらにエッジでのKubernetesにも対応してジョブを運用できるソフトウェアとして紹介されている。マルチクラスター管理、統合化された認証、クラスターを横断するアプリケーションのフェイルオーバーなどが機能として紹介されている。
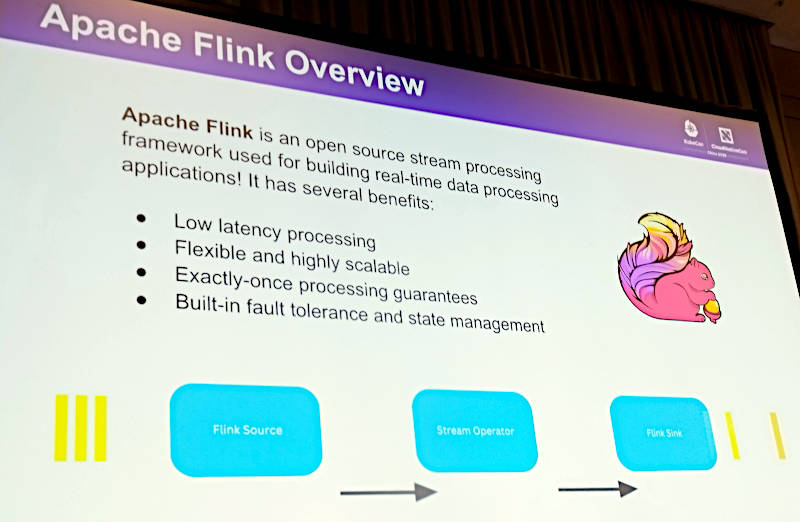
Apache Flinkの概要。高速な処理とフォルトトレーランス、ステート管理がポイント
さらにApache FlinkをKubernetes上で稼働させる場合、Kubernetesの標準的なカスタマイズの方法であるオペレータとカスタムリソースで実装できることが要点だろう。これによってパブリッククラウドでもオンプレミスでも、Kubernetesの作法を知っていれば運用は容易になる。

Kubernetes上のApache Flink。OperatorとCRDで実装
ここでも必要要件であるアプリケーションのリカバリーについて解説を行い、Apache Flinkではノードのハードウェア障害、ネットワーク障害などのクラスター内部での障害に対応してリカバリーできることを説明した。またリソースの使い方についても、Flinkから見えるリソースとKubernetesのリソースをマッチングさせるために「リソースインタープリテーション」、つまりリソースの中身を翻訳する機能について解説を行った。

FlinkのリソースをKubernetesのリソースに翻訳
このスライドではフェイルオーバーというシナリオにおいて、クラスターの状況をFlinkとKubernetesがそれぞれの用語で認識(ヘルスチェック)することで円滑なフェイルオーバーができることを目指すという意味だ。
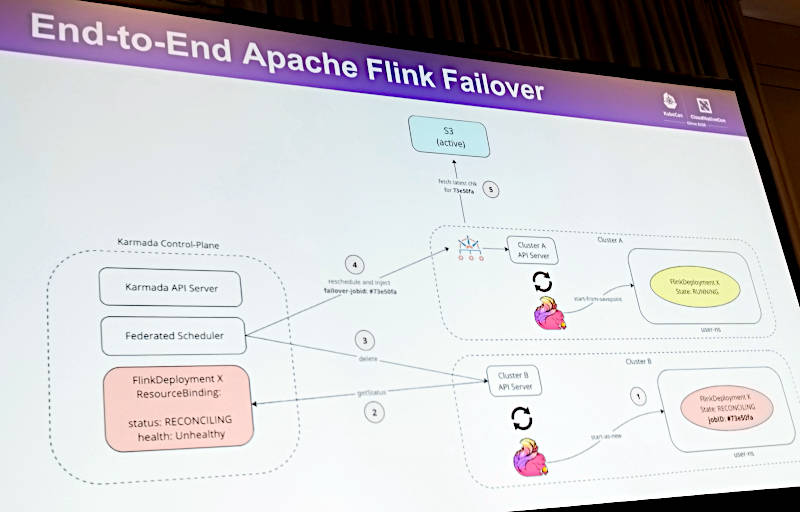
Karmadaが複数のクラスターの状況を確認してアプリケーションをフェイルオーバーする仕組み
このスライドでは、あるクラスターで実行されていたリアルタイム分析のジョブが実行途中に何らかの要因でヘルシーではない状態に陥った際に、それまでの処理データをスナップショットとして保存して、別のクラスターのノードでリスタートする処理が解説されている。

Kubernetesノードのクォータ管理にもKarmadaのCRDが使われる
またアプリケーションがノードに要求するメモリー量やプロセッサのタイプなどのクォータも、KarmadaのCRDを利用することでコントロールできることを説明した。

Apache FlinkがBloombergの要件を満たしていることをまとめとして紹介
Karmadaによって複数のクラスターのエンドポイントを統合的に管理できること、FlinkのCRDによるマッチングに対応していること、自動クラスターフェイルオーバーのサポート、複数のクラスターを横断したクォータ管理などがKarmadaによって実現できることを整理している。

Trinoの概要を解説
TrinoについてはANSI SQLに準拠した分散型のスケーラブルなクエリーエンジンであり、BIツールとも連携できることなどを紹介。そしてKarmadaによってアプリケーションからクラスターを抽象化した発想と同様にTrinoからの検索についてもエンドポイントを抽象化できることを説明した。
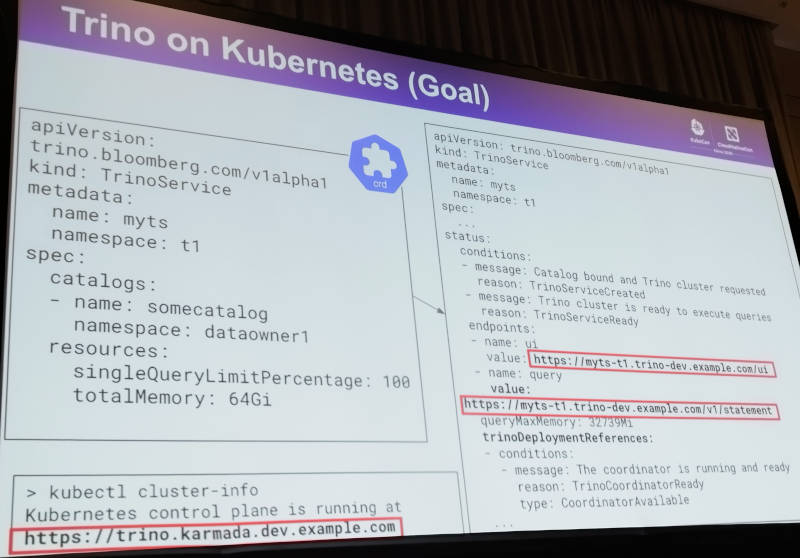
Trinoによって検索のためのエンドポイントを抽象化
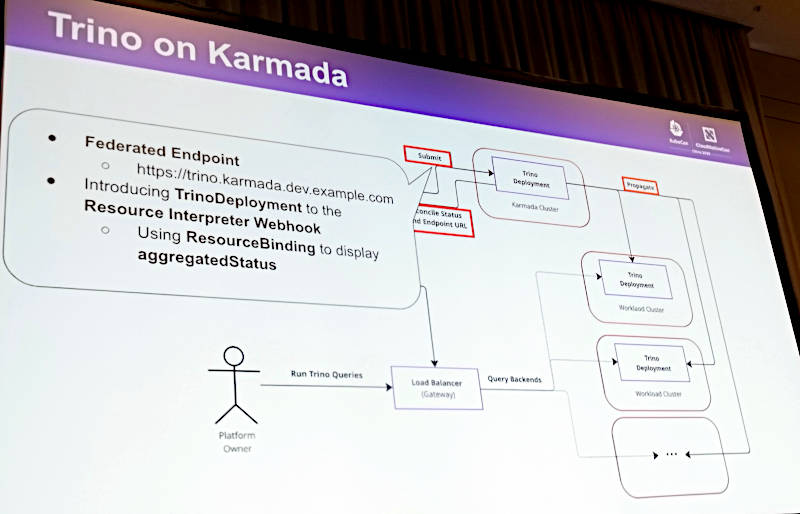
検索に利用するTrinoのエンドポイントを抽象化されている概念図
3つ目のApache Sparkについても簡単に紹介を行った。

Apache Sparkの概要
Sparkはバッチジョブに加えてリアルタイムの分析のためにストリーミングによる対話型のクエリーエンジンとしても利用可能であることが説明されている。また多くのファイルフォーマットとも親和性が高いことが記載されている。

オンラインジョブとバッチジョブで使えるSpark
ここからは、Kubernetes上でSparkがリアルタイムとバッチで実装される場合のCRDなどを解説する内容となった。

バッチでSparkを使う場合の解説
そしてSparkをマルチクラスターで利用する場合にPropagationPolicyというリソースを使うことを解説。
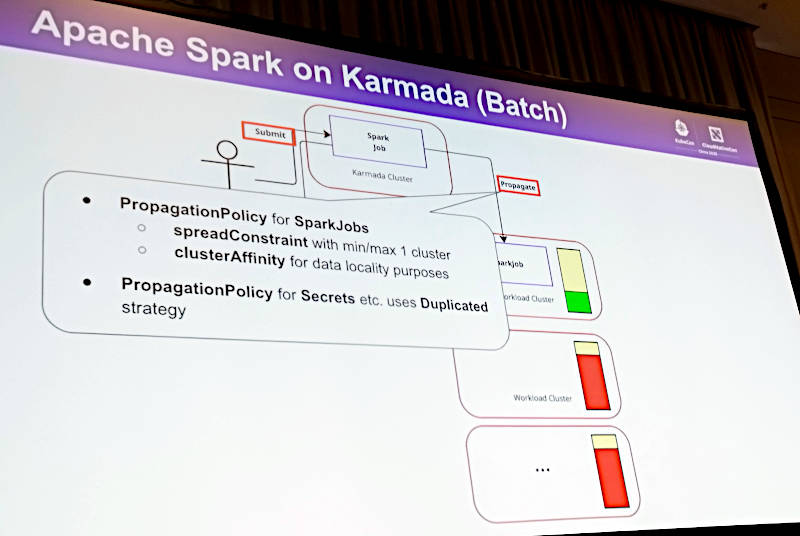
SparkJobsのPropagationPolicyというリソースを使ってKarmada上で制御
ここではリソースの使い方についてその空き状況をどうやって他のクラスターに共有するのか、についてPropagationPolicyというリソースを使って行うことなどが説明されている。
最終的なBloombergのデータ分析システムが複数のクラスター上でKarmadaを使って実装されているアーキテクチャー図を用いて、再度確認。あくまでもKubernetesの設計思想に沿った運用が可能であることで、クラウドネイティブなシステムとして開発運用されていることがわかる。
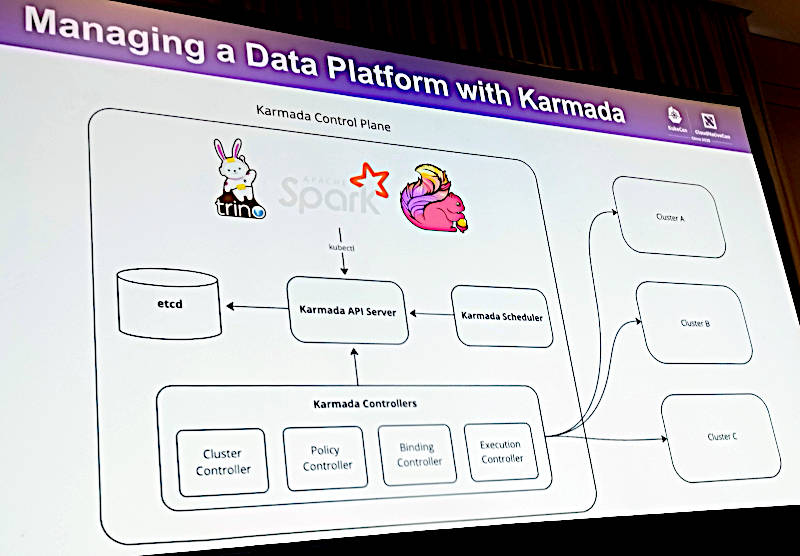
BloombergのKarmadaによるマルチクラスターデータ分析システム
これでアプリケーションデベロッパーも運用管理者も物理クラスターを意識しない抽象化が可能になり、それぞれの要件は満たせたことを紹介。

Karmadaによって要件を満たしていることを確認するスライド
最後にこのシステムの基幹となったKarmadaの将来計画についても簡単に紹介した。現行の1.11から1.12、さらに1.15以降まで、ある程度は機能強化のシナリオはできているようだ。Karmadaは元々Huaweiによって開発され、CNCFに寄贈されたことでマルチクラスター管理の注目株となったものだが、Huawei以外の企業からのコントリビューションも増えていると思われる。実際KubeCon Chinaでは、多くの大規模なユースケースにおいてKarmadaが使われていることを紹介するセッションが目についた。
Karmadaの概要については2025年のKubeCon Europe 2025でHuaweiとBloombergのエンジニアが一緒に解説を行っているので、そちらも参考にされたい。
●動画:Multi-cluster Orchestration System: Karmada Updates and Use Cases


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています




全文検索エンジンによるおすすめ記事
- KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
- KubeCon EU 2021でRed Hatが発表した複数のKubernetesを制御するkcpを紹介
- KubeCon NA 2024開催、前日の共催カンファレンスからAIワークロードのスケジューリングに関するセッションを紹介
- KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
- KubeCon North America 2024からAIワークロードのスケジューリングに関するセッションを紹介
- KubeCon NA 2020 LinkerdとAmbassadorを使ったマルチクラスター通信を紹介
- KubeCon China 2025、中国のショートビデオサイトによるMLOpsのユースケースセッションを紹介
- KubeCon North America:座談会で見えてきた退屈なKubernetesの次の世界
- KubeCon China:中国ベンダーが大量に登壇した3日目のキーノート
- KubeCon China:恒例の失敗談トークはスナップショットの実装について