【日本発 生成AIの夜明け】国産生成AIの「今」と次の一手

はじめに
本連載では、生成AIコミュニティ「IKIGAI lab.」に所属する各分野の専門家が、それぞれの視点から最新のAIトレンドとビジネスへの示唆を発信しています。本記事を通じて、皆さまが“半歩先の未来”に思いを馳せ、異なる価値観や視座に触れていただければ幸いです。
ここ1年で、生成AIは「遠い話」から、メール下書きや議事録要約など日常業務のすぐ横に来ました。同時に、「社内情報は安全か」「日本語の敬語や文脈に強いか」「突然の仕様変更に振り回されないか」という不安も膨らんでいます。
だからこそ今、国産・国内生成AIに注目する意義が生まれています。本稿では政策・事業の観点から国内の生成AI動向についてまとめます。
政策・政府動向
政府「AI戦略本部」始動とAI基本計画(年内策定方針)
政府は2025年9月12日「人工知能戦略本部」を初開催し、年内にAI基本計画をまとめる方針を示しました。この方針は(1)“信頼できる国産AI”の開発支援、(2)横断規制の見直し、(3)省庁横断の推進体制の明確化の3点が軸となっています。計画段階から産業実装を意識し、官民連携と実証で早期の社会実装を図る構えです。
内閣府の公式トピックスでも、AI法の全面施行(9月1日)と本部発足(9月12日)が明記され、制度・組織面が整いつつあることが確認できます。投資やデータガバナンス、計算資源の整備、そして日本語圏に最適化された基盤モデルの確保が重点で、国の“自律性”を押し上げつつ、民間のスピードを阻害しないルール設計へ舵を切りました。この流れは、年末の計画取りまとめに向け、具体化フェーズへ進む見通しです。
【出典】「国産AI開発支援、年内に基本計画策定へ 政府本部が初会合開催」(日本経済新聞 2025/09/12)
「国産AIに政府が本格着手」報道と市場の反応
9月中旬、読売新聞が「政府は自国のデータや技術をもとにした国産AIの開発に乗り出す」と報道しました。市場では半導体・データセンター関連株が物色されるなど、政策期待が即時に波及しました。
記事は、国内データ・国内クラウド・国内モデルを重ねる“国内完結”型の方向性を示唆し、経済安全保障やサプライチェーンの観点からも注目を集めます。並行して内閣府はAI法の全面施行と本部発足を公表しており、制度面の裏付けが整備されつつあることが確認可能です。政策のフォワードガイダンスが市場心理を押し上げ、民間投資と技術連携の呼び水になった点が今回の特徴と言えます。
【出典】「国産AI開発を政府が支援へ、学習データ提供し資金面も後押し…アメリカや中国依存を懸念」(読売新聞オンライン 2025/09/18)
「AI for Science」:
不可欠性の構築と“持つ国”への分岐点
日本が「AI for Science」を推進するうえでの焦点は、単に自国で基盤モデルを“持つ”だけでなく、国際連携の中で“不可欠性”をどう作るかにあります。米中の巨額投資と比べ、金額で並ぶのは現実的ではありません。ゆえに、生命科学や材料など日本の専門分野の強みやデータ、アプリ開発・セキュリティ等の総合力を束ね、相手国が切れない役割(不可欠性)を明示する必要があるという指摘です。
国内の大学・研究機関では実装や自動実験を担うエンジニア層が不足し、構造課題も横たわる。基盤モデル・計算資源・半導体・エネルギーの多層で海外依存が大きい現実を踏まえつつ、政策官・大学執行部・研究者が中長期の戦略と役割分担を共有し、日本語基盤モデルや研究用モデルをテコに“設計・開発を主導する側”に回るべきだと論じています。
【出典】「AI for Science 問われる研究企画力(上)日本、AI基盤モデル構築へ 大国と組む「価値」磨く」(日刊工業新聞 電子版 2025/10/08)
事業動向
ソフトバンク「Sarashina」:ソブリンAIを成長ドライバーに
SB Intuitionsの丹波氏インタビューでは、2024年度に4,600億パラメータの基盤モデル「Sarashina」を完成、700億パラメータの「Sarashina mini」を社内運用しつつ、2025年秋の商用化を見据える構想が語られます。巨大な“先生モデル”から“生徒モデル”を蒸留し、多様なニーズに最適化する設計思想を採用。社内の厳しい目で毎週の改善を回し、満足度を着実に引き上げてきたといいます。
マルチLLM戦略の中核として、日本語・日本文化への適合性と“ソブリンAI”(主権性)を強みとし、将来は700億級の専門家集団を束ねた1兆パラメータ級への展開も視野にあるとのことです。海外LLM依存のリスクを減らし、国産エコシステムの土台を築く狙いが明確です。
【出典】「国産生成AI 開発責任者インタビュー統合報告書 2025」(SoftBankFT BANK 2025)
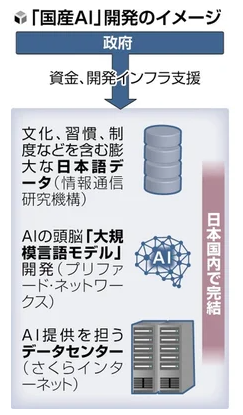
「国内で完結」する生成AIエコシステム
CNET Japanは、PFN・さくらインターネット・NICTの3者が「安心安全で日本社会と調和する国産生成AIのエコシステム」構築で基本合意したと報道しました。3者は国産生成AIのエコシステムを“国内完結”で構築する取り組みを進める活動の中で合意に至りました。
この報道のポイントは(1)PFN×NICTが日本語性能に優れた後継LLM群を共同開発、(2)さくらの生成AIプラットフォームで提供し、クラウドからアプリまで“完全に国内で完結”する活用を可能にという設計である点です。
国内データ/国内クラウド/国内モデルのレイヤーをつなぎ、法制度・文化・商習慣に適合したトラストを確保しつつ、商用提供まで見据えています。国産の計算・データ・モデルを束ねる実装文脈として、政策の“自律性”を民間が実現に落とす好例と言えます。
【出典】「さくらインターネット、国産生成AI構築へ合意-クラウドからアプリまで「完全に国内で完結」」(CNET Japan 2025/09/18)
日本語コピーライティング特化型生成AI
(電通×ソフトバンク×SB Intuitions)
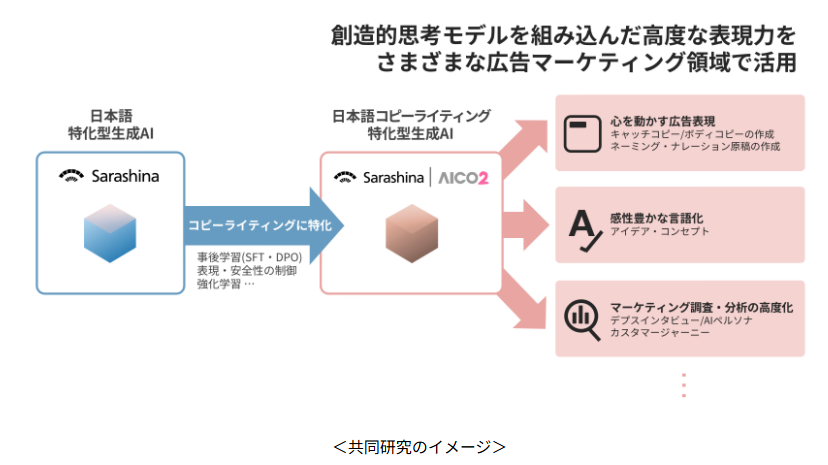
電通・電通デジタル・ソフトバンク・SB Intuitionsの4社は、日本語の語感や繊細な表現を捉える「日本語コピーライティング特化型生成AI」の共同研究を開始しました。
電通側のコピー知見や生成ツール群(例:AICO2)、ソフトバンクの計算基盤、SB Intuitionsの日本語LLM「Sarashina」を組み合わせ、マーケティング目的やターゲットに応じたトーン制御、自己評価による表現学習などで広告コピーの実運用精度を高めます。
海外汎用LLMだけでは届きにくい“日本語らしさ”に踏み込み、クリエイティブ現場の生産性と発想拡張を両立させる狙いです。
【出典】「「日本語コピーライティング特化型生成 AI」の開発に向けた共同研究を開始 - News(ニュース)」(電通ウェブサイト 2025/09/25)
自治体向け「zevo」:LGWANで最新モデルを安全活用
シフトプラスの「自治体AI zevo」は、LGWAN環境でChatGPT/Claude/Geminiなどを扱える自治体向け基盤です。2025年8月には「GPT-5/mini/nano/chat」の4モデルが追加され、選択肢の拡充とコスト効率の向上をアピールしています。LGTalk連携やファイル無害化などセキュリティ配慮の周辺機能も併せて提供されました。
自治体の現場業務で“安全に最新を使う”ルートを確保しつつ、ナレッジ蓄積や定型業務の効率化を進める構えです。国産LLMとの併用やワークロード分担を前提に、用途別に最適モデルを切り替える“マルチAI”実務が加速しています。
【出典】「自治体AI zevoにて、GPT-5シリーズが2025年8月8日(金曜日)より4モデル利用可能に!〜GPT-5/mini/nano/chatの4モデルが追加〜)」(PRTIMES 2025/08/12)
今後の潮流
法制度のフェーズ移行
AI法が全面施行され、AI戦略本部が動き出したことで、「実装目線のガバナンス」が前提になります。透明性・認証・学習データの権利処理といった論点が、基本計画の下で産業実装と同期して具体化される見込みです。
モデル運用の効率化
NTTは、基盤モデルを更新しても特化モデルの再学習を不要にする「ポータブルチューニング」を発表しました。学習結果を別モデルへ移植できるため、停止時間とコストを大幅に抑えられます。
企業は“モデル乗り換え”や“複数モデル併用”を柔軟に計画でき、継続運用性が高まります。今後はモデル更新のサイクルが短くなり、停止時間と運用コストをどこまで抑えられるかが競争力の差になっていきます。
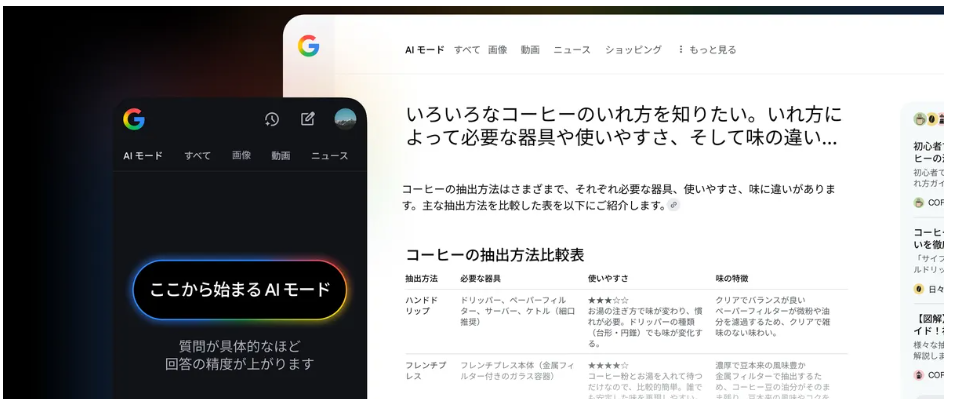
検索の“生成化”
Googleは検索の「AIモード(日本語)提供を開始し、回答提示型の探索が一般化しつつあります。企業や自治体の情報発信は、SEOだけでなく生成AI最適化(AIO)」や責任ある運用の整備が重要になります。
国産モデル活用と合わせ、発見される設計が求められます。この流れにより、AIに“見つけてもらい正しく要約される”ことが成果の出発点となり、コンテンツの構造化や出典明記が標準になっていきます。
【出典】
「AI法 全面施行 -次なるフェーズへ-」(内閣府 2025/10/03)
「NTTが特化型生成AIの技術を開発、基盤モデルの再学習コストを無くす」(日経クロステック(xTECH)2025/07/09)
「Google 検索における「AIモード」を日本語で提供開始」(Google Japan Blog 2025/09/09)
おわりに
本記事では、政府の動き(AI戦略本部・基本計画)と、Sarashina、PFN×NICT×さくら、自治体向けzevoといった事例を手がかりに、国産・国内の生成AIが「試せる」「使える」段階へ進んだことを整理しました。
要点は、安心して使えるルールづくり、運用を止めない仕組み(ポータブルチューニング等)、目的に応じたマルチAIの選択、そして検索の“生成化”に合わせた情報発信の見直しです。認証やデータ権利、評価・監査、人材育成、計算資源の確保を地道に進めながら、現場では小さく始めて学びを積み上げるこの往復が成果を早めます。国内の生成AI活用はここからが本番です。

連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています





全文検索エンジンによるおすすめ記事
- 【日本上陸の衝撃】OpenAI上陸で変わる日本のAIビジネスの在り方
- 生成AI向け機械学習クラスター構築のレシピ 北海道石狩編
- 【EUのAI法に習う】欧州における生成AIと法制度の協調モデル
- LFが「オープンソースAIにおけるグローバルな協業のための戦略的方向性の策定」日本語版を公開
- 【知っておきたい】DeepSeekの衝撃とChatGPTの新機能、何が変わった?
- 大規模言語モデルの概要
- 【ChatGPT超進化!】最新トレンド「AIエージェント」の全貌と実践的活用法
- 【Perplexity AI】が拓く次世代AIリサーチの可能性
- ELYZA、700億パラメータの大規模言語モデル(LLM)「ELYZA-japanese-Llama-2-70b」の開発を発表
- 【やってみた】GPT-5×Google AIの進化―プレゼン資料も爆速作成