Community Over Code Asia 2025から異機種GPU対応のスケジューラーHAMiのセッションを紹介

The Apache Software Foundation(ASF)が主催するオープンソースカンファレンスCommunity Over Code Asia 2025から、GPUのスケジューリングに関するセッションを紹介する。
このセッションは「Maximize utilization of Heterogeneous AI devices on Kubernetes with HAMi」と題されており、Kubernetes配下で異機種のGPUの稼働を最適化するツールHAMiを紹介するものだ。プレゼンターはDynamia.aiのエンジニアであるLi Mengxuan氏だ。Dynamia.aiはHAMiの開発元としてこのプロジェクトを推進する企業だが、現在HAMiはCNCFのサンドボックスプロジェクトとして採用されている。またDynamia.aiはオープンソースのHAMiと商用版のDynamia.aiの2本立てでビジネスを展開している。いわば、オープンソースに対して機能を強化したエンタープライズ版としてDynamia.aiという会社名と同じソフトウェアに価格を付けて販売しているということだろう。以下のサイトにはオープンソース版とエンタープライズ版の機能の違いが説明されている。
●参考:Dynamia AI Products - Enterprise Heterogeneous Computing Platform
ちなみにHAMiは「heterogeneous AI computing virtualization middleware」というソフトウェアの中身を表す英文から取られているようだ。なお以前は「k8s-vGPU-scheduler」という名称で知られていたソフトウェアでもある。

セッションのタイトルスライド

プレゼンターであるLi Mengxuan氏
このカンファレンスはASFのものであるが、GPUスケジューリングに対してCNCFのプロジェクトを題材に持ってくることは生成AIが主要なトピックとなっている現在では妥当なセッションということだろう。ビッグデータもさることながら生成AIがKubernetesで実装されることは、モダンなITインフラストラクチャーとしては必要であることがわかる。
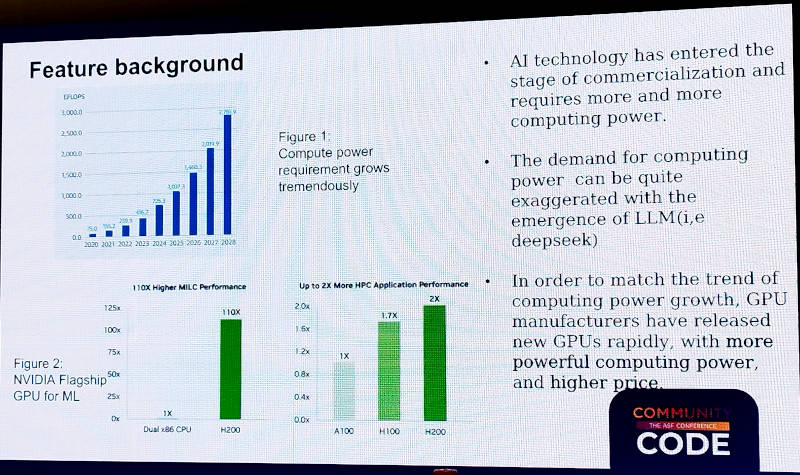
GPUの最適なスケジューリングが必要な背景を説明
Mengxuan氏はこの機能が求められる背景を説明。生成AIによって巨大なコンピューティングパワーが必要となっている昨今、NVIDIAを始めとする数多くのベンダーがGPUを開発し、リリースしているという状況ではあるものの、必要なGPUをすぐに調達できるとは限らず、それゆえ保有する異なるGPUをいかに効率良く使うのか? が課題となっていると説明。
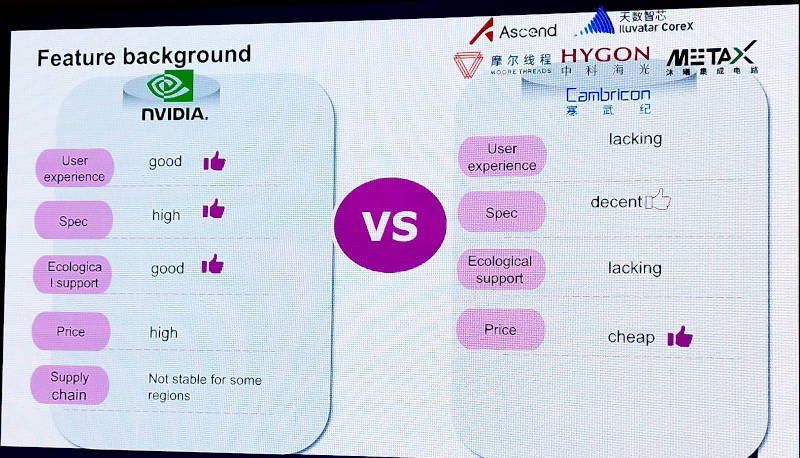
NVIDIAと他のGPUメーカーを比較
GPUそのものはNVIDIAだけが開発しているのではないため、ここではHuaweiによるAscend、Moore Threads、HYGON、Lluvatar Corex、MetaX、CambriconなどのメーカーがNVIDIAとの比較に挙げられている。なお、ここにIntelとAMDが含まれていない理由は最後に明らかになる。ここでは中国国内のファブレスを含む半導体メーカーを挙げて、アメリカ資本のNVIDIAによって支配されているGPU市場に対して中国メーカーという選択肢を与えた形になっている。ここでNVIDIAの欠点として価格、市場での調達性が挙げられているのはごく妥当だが、中国の競合メーカーに対しては性能面ではNVIDIAに比べても優ってはいないが劣らないというDecentという評価を与え、価格については安価であるという評価を与えている点は興味深いところだ。ユーザー体験とサポートについては、負けているとは言いながらも今後の進展に期待していることの表れだ。
そして現在の課題としてGPUの活用の度合い、つまり稼働率が低いことを挙げた。

GPUの稼働率が低いことが大きな問題点
ここではKubernetes配下でGPUを利用する際の稼働率を示して、理想的には100%の稼働を期待したとしても実際は10%以下の稼働率に留まっていることを説明した。またGPUのメーカーの違いによってもそれぞれ最適化に違いがあるため、運用上の課題が残ってしまうことを説明し、異機種GPUの最適化が難しいことを示した。
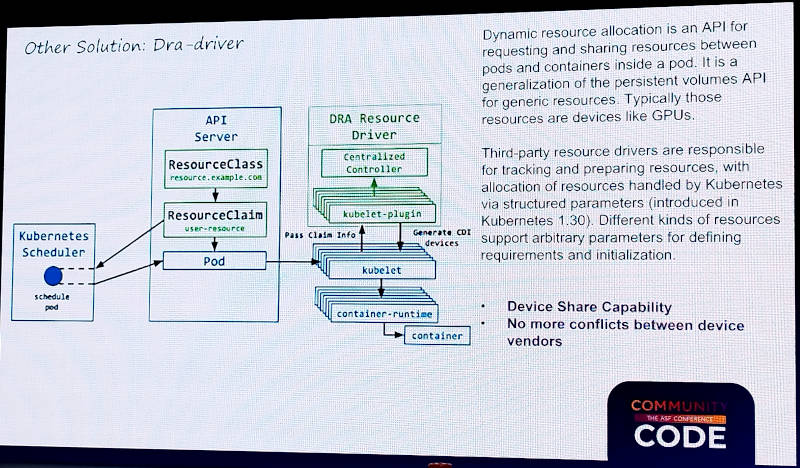
GPU最適化の方法を解説。ここではDRAによる最適化を紹介
最初の解決案の一つはKubernetesのDynamic Resource Allocation(DRA)を使うことだ。ただしDRAを使用するためにはKubernetesのバージョン1.32以上が必要であり、新たなリソースを運用する必要があること、まだこれに対応するGPUメーカーが多くないことなどを欠点として挙げた。
そこからDynamia.aiとしての解決策として紹介されたのがHAMiだ。HAMiは軽量かつプラグインとして利用できる構造を取っていることが利点として挙げられている。またWebベースのステートレスアプリケーションのプラットフォームとしてのKubernetesに加えて、バッチジョブのスケジューラーであるVolcanoにも対応することで、生成AIで最もGPUが使われる学習プロセスにおいて異機種GPUをフル活用することが可能であることも示されている。
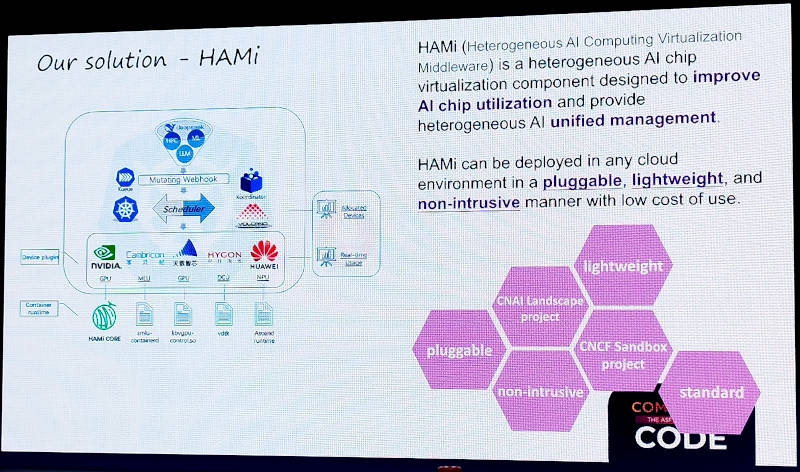
KubernetesとバッチジョブのVolcanoに対応する異機種GPUスケジューラーHAMi
HAMiはGPUの共有、より高度なスケジューリング、モニタリングなどの機能をすべて含んだスケジューラーであると説明されている。

3つの機能を統合したスケジューラーHAMi
GPUデバイスの共有について説明したスライドでは、従来の方法ではGPUそれぞれにプロセスが割り当てられ稼働率が低いままだったものをHAMiによって空いているGPUにプロセスを割り当てることで単体のGPUの稼働率を高め、空いたGPUを他のタスクに使わせることが可能になると説明。

HAMiによるGPUの共有の解説
HAMiの内部について解説を行い、CUDAからの命令をHAMiが途中でハイジャックすることでアプリケーションを変えずにGPUの共有が可能になるという。この例ではNVIDIAのCUDAの命令をHAMi-Coreが持つlibvgpu.soというプラグインが共有の部分を実装していることを説明した。
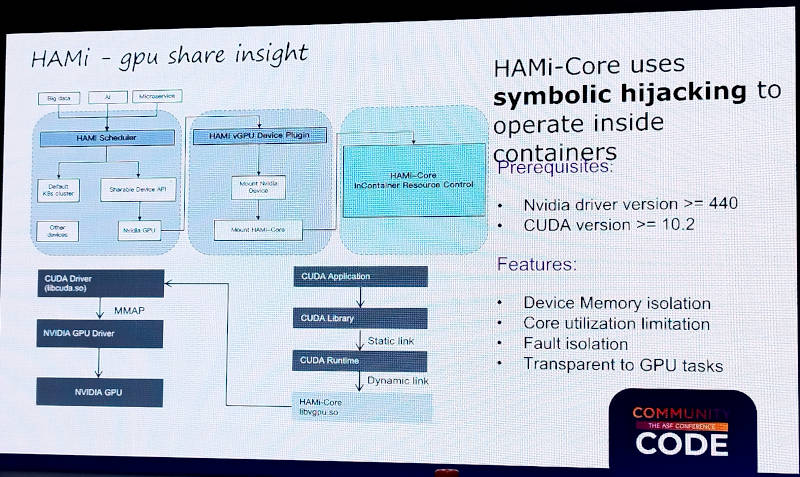
HAMiとNVIDIAのCUDAの関係をレイヤーに分けて説明
ここではNVIDIAのGPUとHuaweiのAscendのGPUに対する記述のそれぞれについて例を挙げて説明した。

HuaweiのAscend GPUに対するManifestoを紹介して記述の例を解説
またタスクの優先度に関してもNVIDIAの例を挙げて説明。
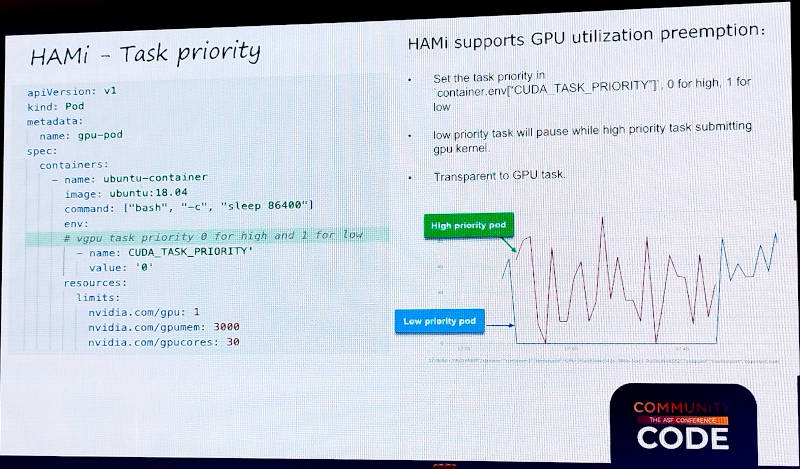
NVIDIAのGPUに設定された優先度はHAMiにおいても利用可能であると説明
GPUの割り当てについてはノード単位とGPU単位においてBinpackとSpreadを説明。ここではBinpackは複数のプロセスを隙間なく割り当てること、Spreadはノード及びGPUにプロセスを分散させることを意味している。

BinpackとSpreadでノードとGPUの稼働率を調整
またHAMiはNUMAメモリーにも対応していることを説明。ここではGPUがNVLinkで接続された構成において、そのトポロジーを理解して最適な割り当てが可能であると説明した。
さらにHAMiはQoSベースでKubernetesのタスクをスケジューリングするKoordinatorの中でも使われていると説明。KoordinatorもCNCFのサンドボックスプロジェクトだ。
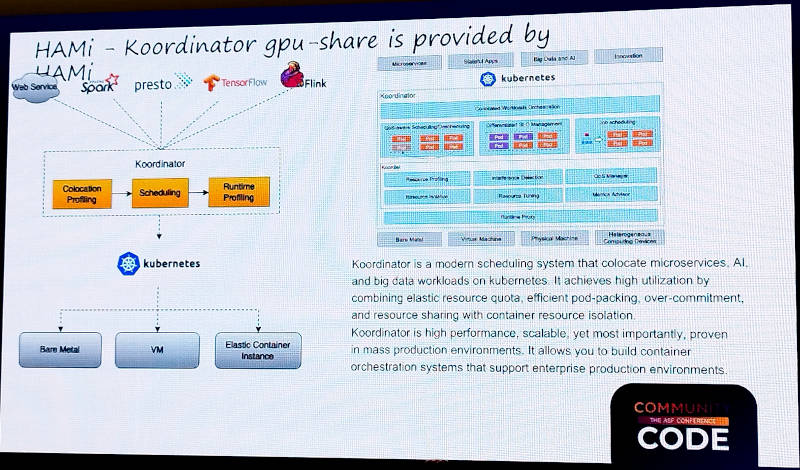
KoordinatorでもHAMiが使われていると説明
次にユースケースとしてDeepSeekの各モデルをホスティングするサービスを展開しているCoresHub(中国名:基石智算)を挙げて説明。CoresHubはNVIDIAのH100よりも前の機種として保有しているH800(対中輸出規制に対応したモデル)の稼働率が低かったという。しかしHAMiによってその稼働率を上げることで、約3倍の売上が達成できるようになったことがスライドに記載されている。つまり基石智算は、中国国内ではユースケースになり得るGPUサービスのプロバイダーであることがわかる。実際に稼働率の低いGPUの稼働率を上げることで売上が3倍に伸びるなら新しいツールを使うことは理に適っている。
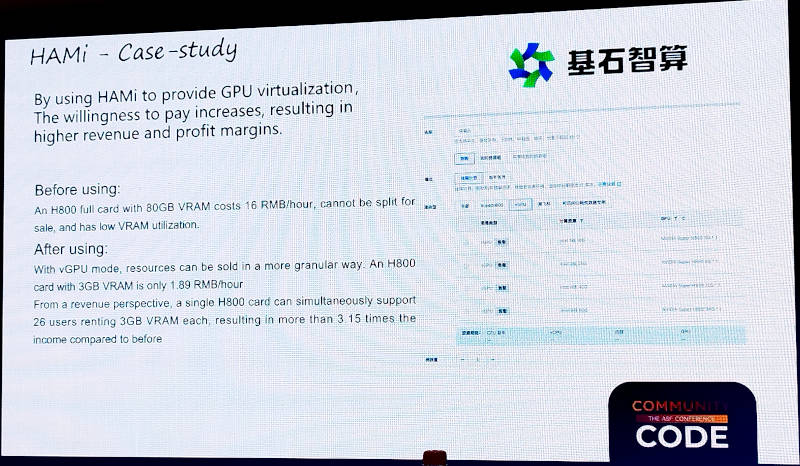
ユースケースを紹介。GPUサービスの稼働率を上げて売上を3倍に伸ばした
他にも中国国内に多くのユーザーが存在するとして紹介されたスライドでは、WeiboやDaoCloud、iFLYTEKなどクラウドネイティブなカンファレンスではよく見かける会社以外にも多くの中国企業、大学の名前が挙げられている。
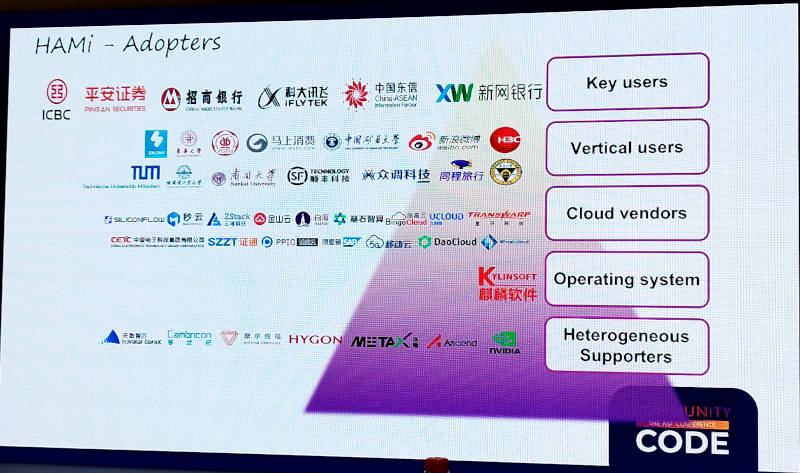
HAMiのユーザーを一覧で紹介
最後にこれからのロードマップを紹介。
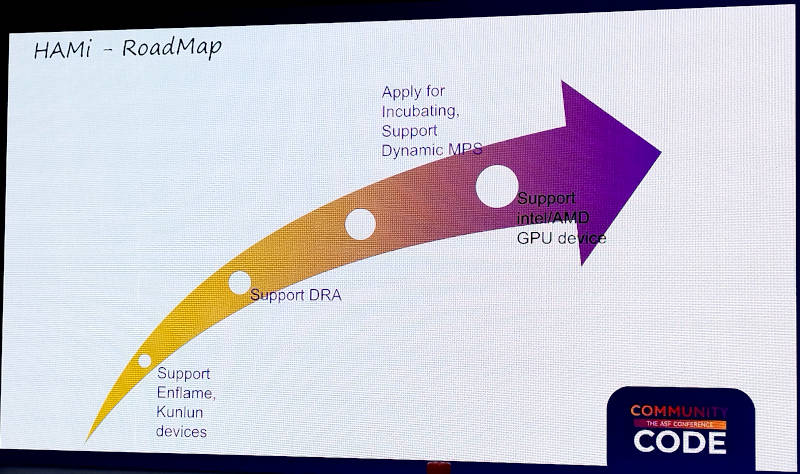
HAMiのロードマップ
ここではAscendやHYGONなどのGPUに加えてEnflameやKunlunxinのGPUなど、中国製GPUへの対応を直近の機能拡張として挙げている。またKubernetesのDRAのサポート、CNCFのインキュベーションプロジェクトへの昇格、さらにIntelやAMDのGPU対応などが項目として紹介されている。つまり現時点ではNVIDIAと中国製のGPUにのみ対応しているという状況であることがわかる。この後には参加者からの質問に答える時間となり、非常に活発な質疑応答が行われていた。
全体として生成AIでGPUを使う場合には日本ではまだNVIDIA一択という状況だが、中国ではアメリカ政府からの輸出規制も関連して中国のGPUベンダーを使いたいというニーズが高まっていることは当然の流れだろう。実際に多くの中国発のGPUベンダーが競い合ってチップやサーバーを製造し、ソフトウェア面でもクラウドプロバイダーが効率的なGPUサービスを構築して提供する状況ではHAMiの登場は必然と言える。IntelとAMDよりも中国ベンダーを優先することで、中国ではより大きなユーザー層を獲得することが期待されている。HAMiだけではなく中国発のGPUベンダーにも注目していきたい。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています




全文検索エンジンによるおすすめ記事
- KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
- 写真で見るKubeCon+CloudNativeCon China 2025
- KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
- KubeCon China 2024、GPUの故障を検知するOSSを解説するセッションを紹介
- 複合並列コンピューティングの必要性とFermiの登場
- KubeCon Europe 2024に日本から参加したメンバーで座談会@桜の木の下
- GTC 2019ではFacebook、Google、Walmartなどによる人工知能関連のセッションが満載
- GPUコンピューティングのNVIDIA、OpenStackでの利用拡大を狙う
- KubeCon Europe 2025、3日目のキーノートでGoogleとByteDanceが行ったセッションを紹介
- GPUコンピューティングの歴史とCUDAの誕生